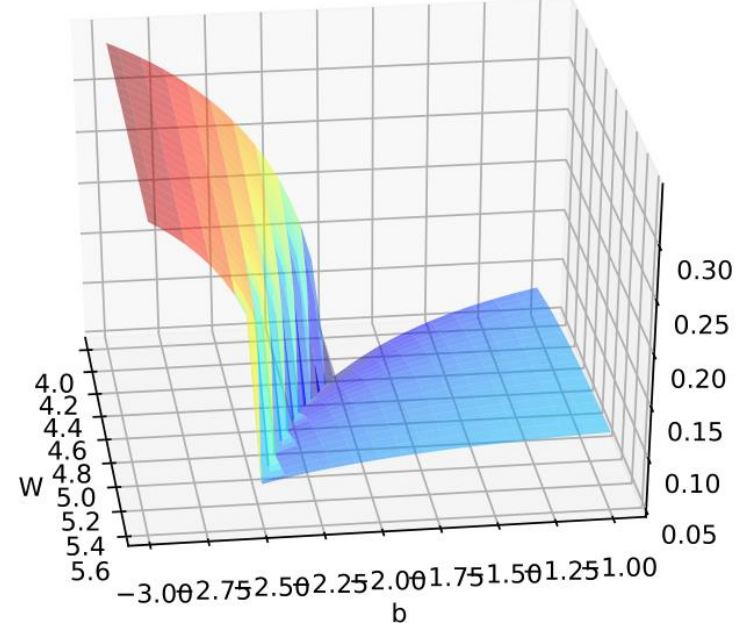
MLP与优化算法
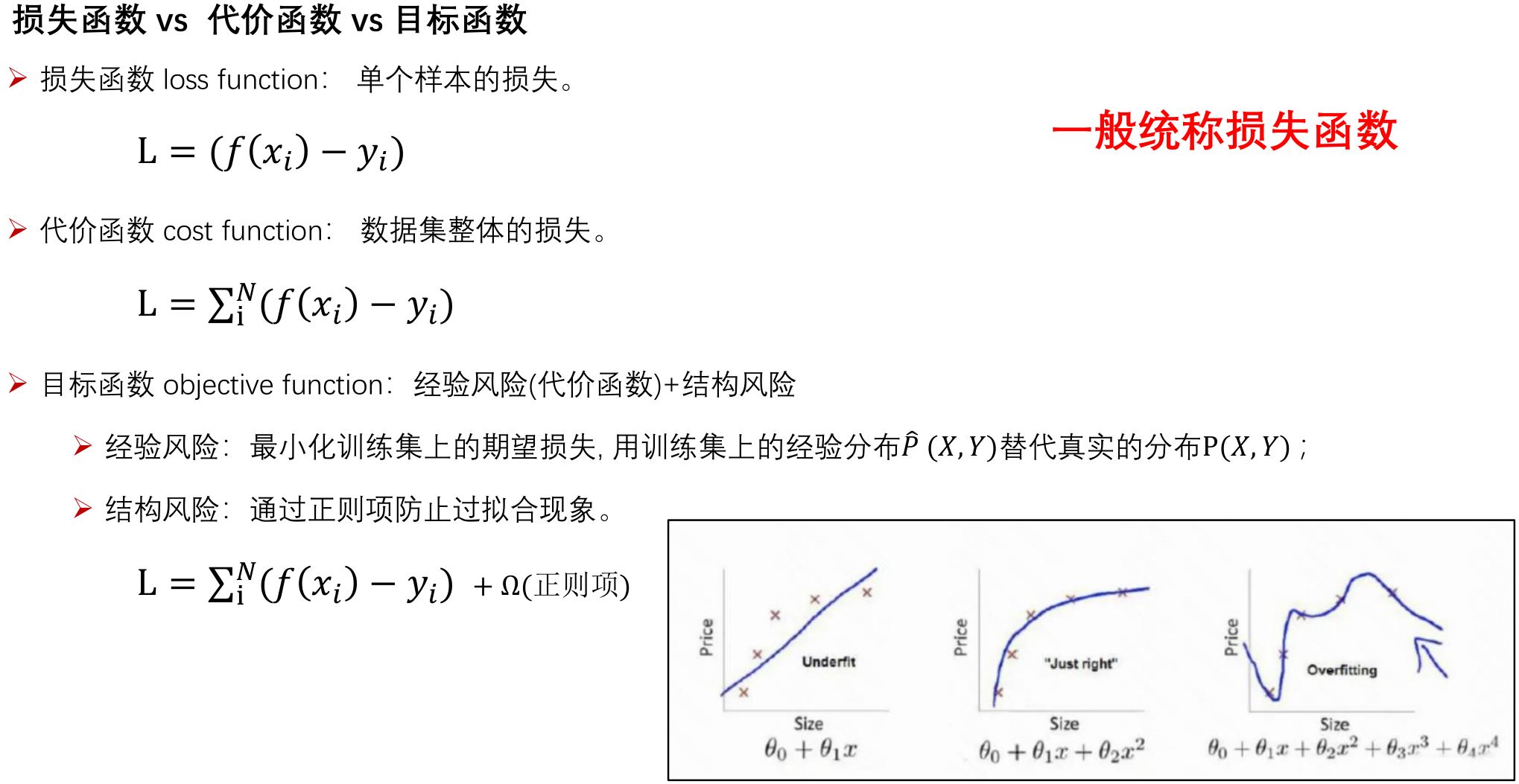
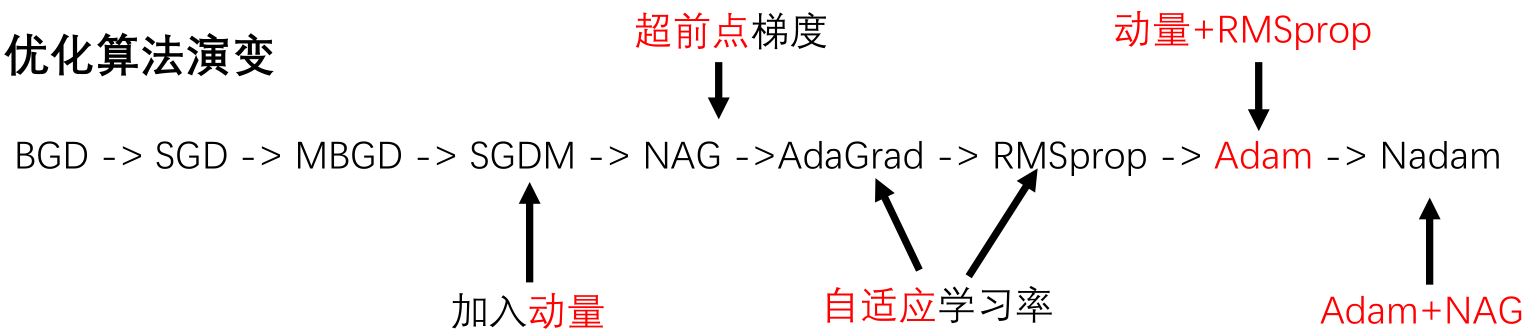
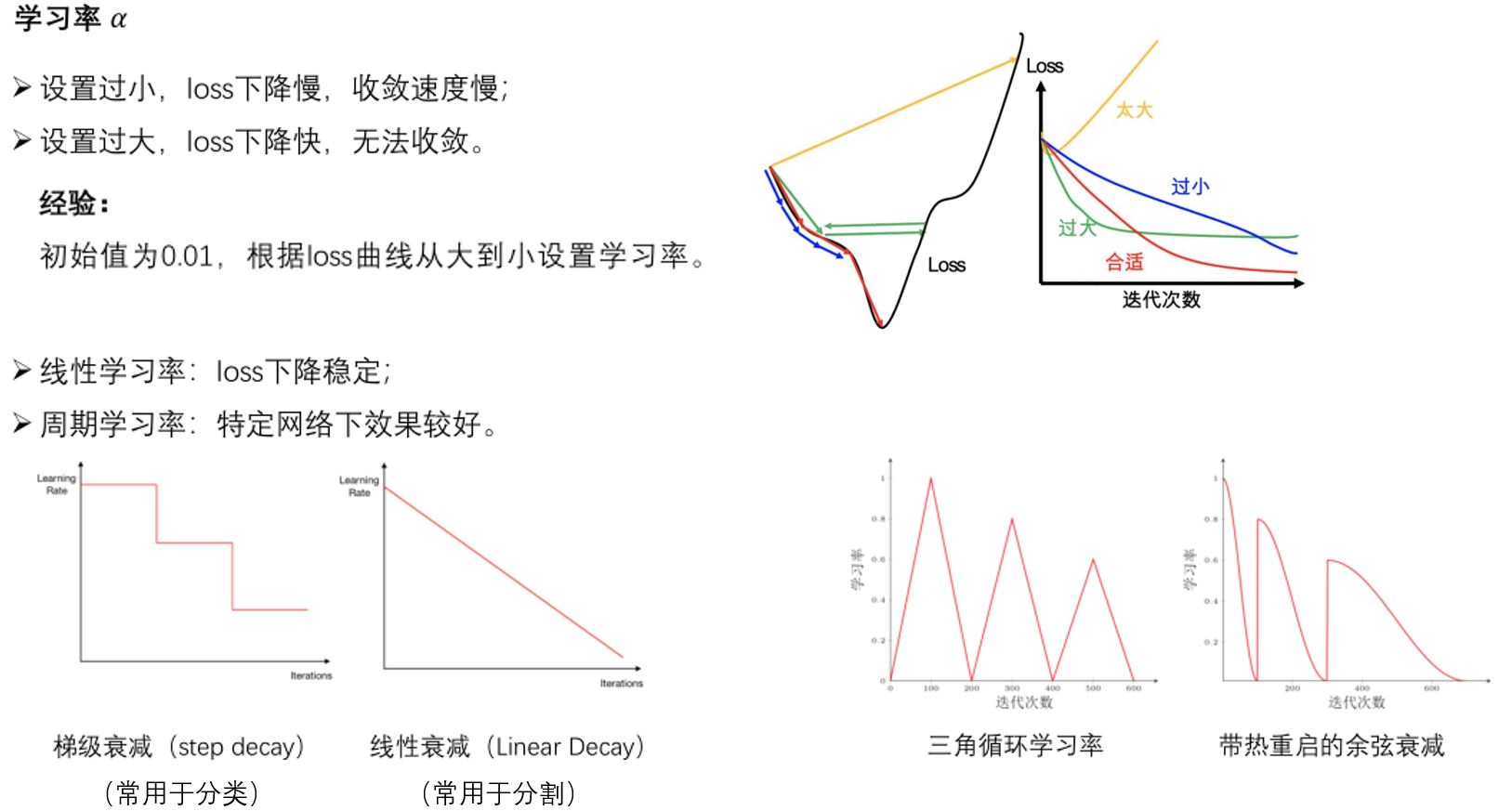
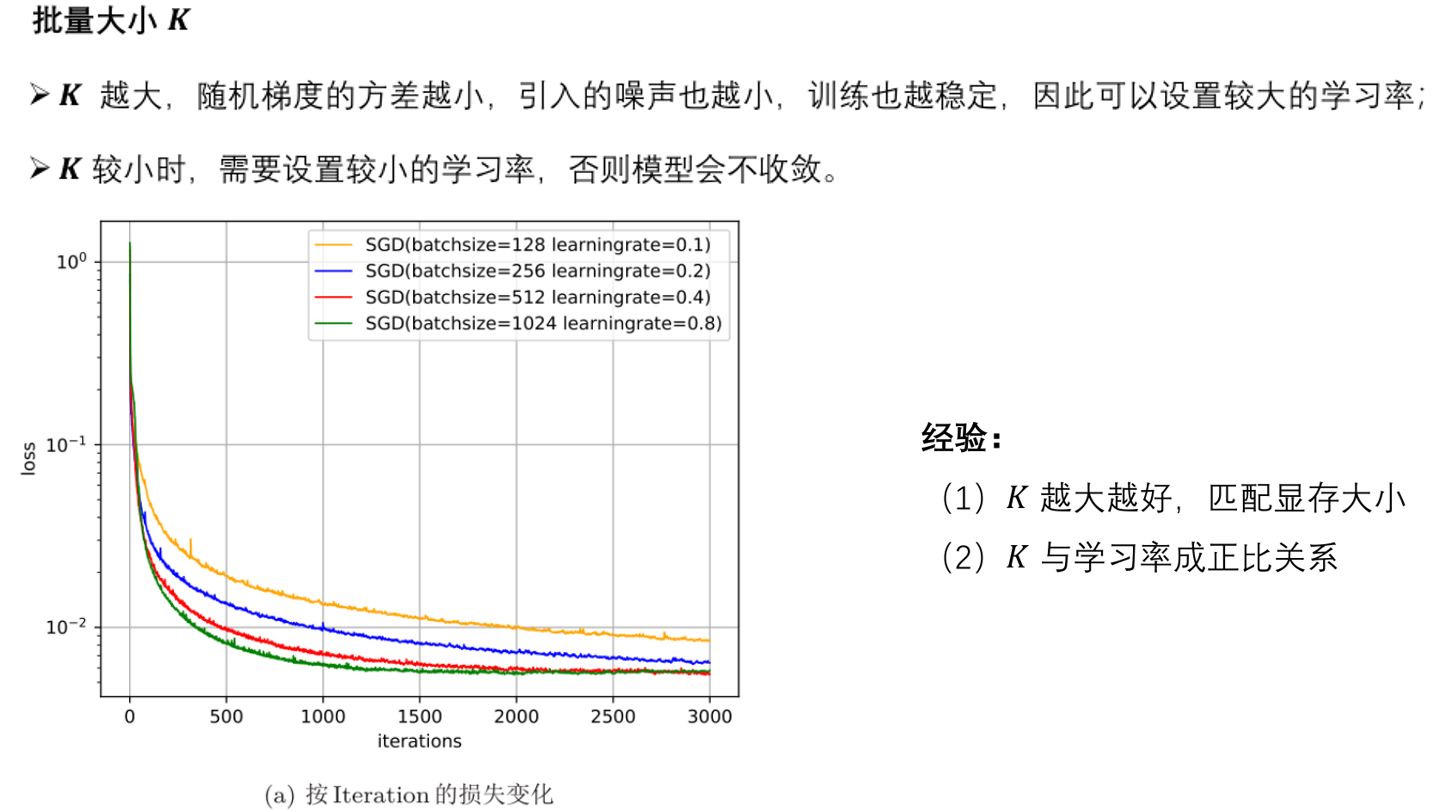
2.1 SGD家族

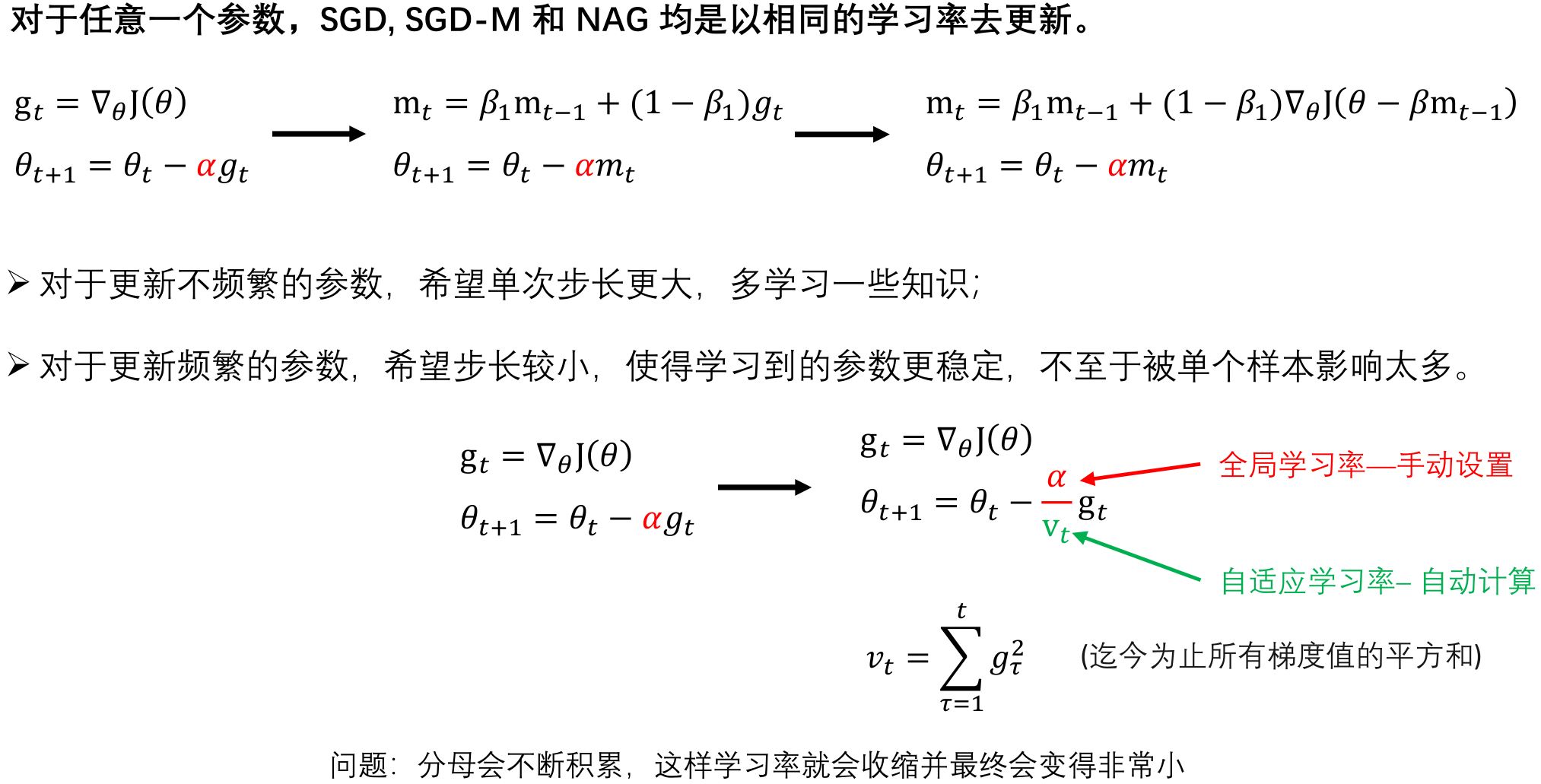
缺点:梯度方向:收敛速度慢,可能在鞍点处震荡; 学习率:需要手动设定,非最优。
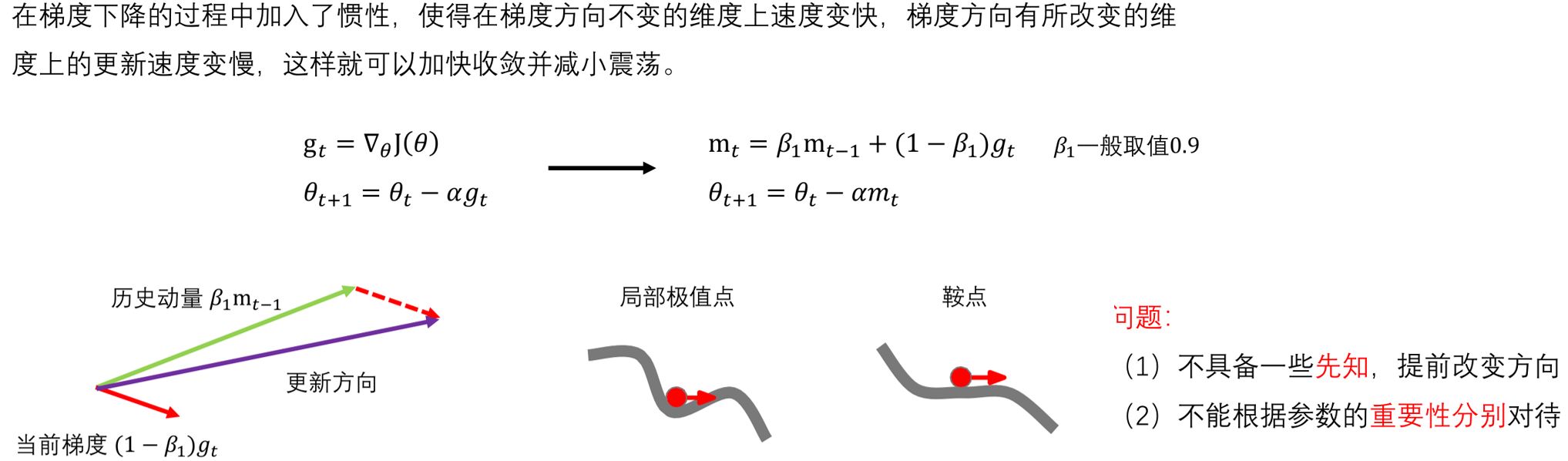
2.2 SGD with Momenturn
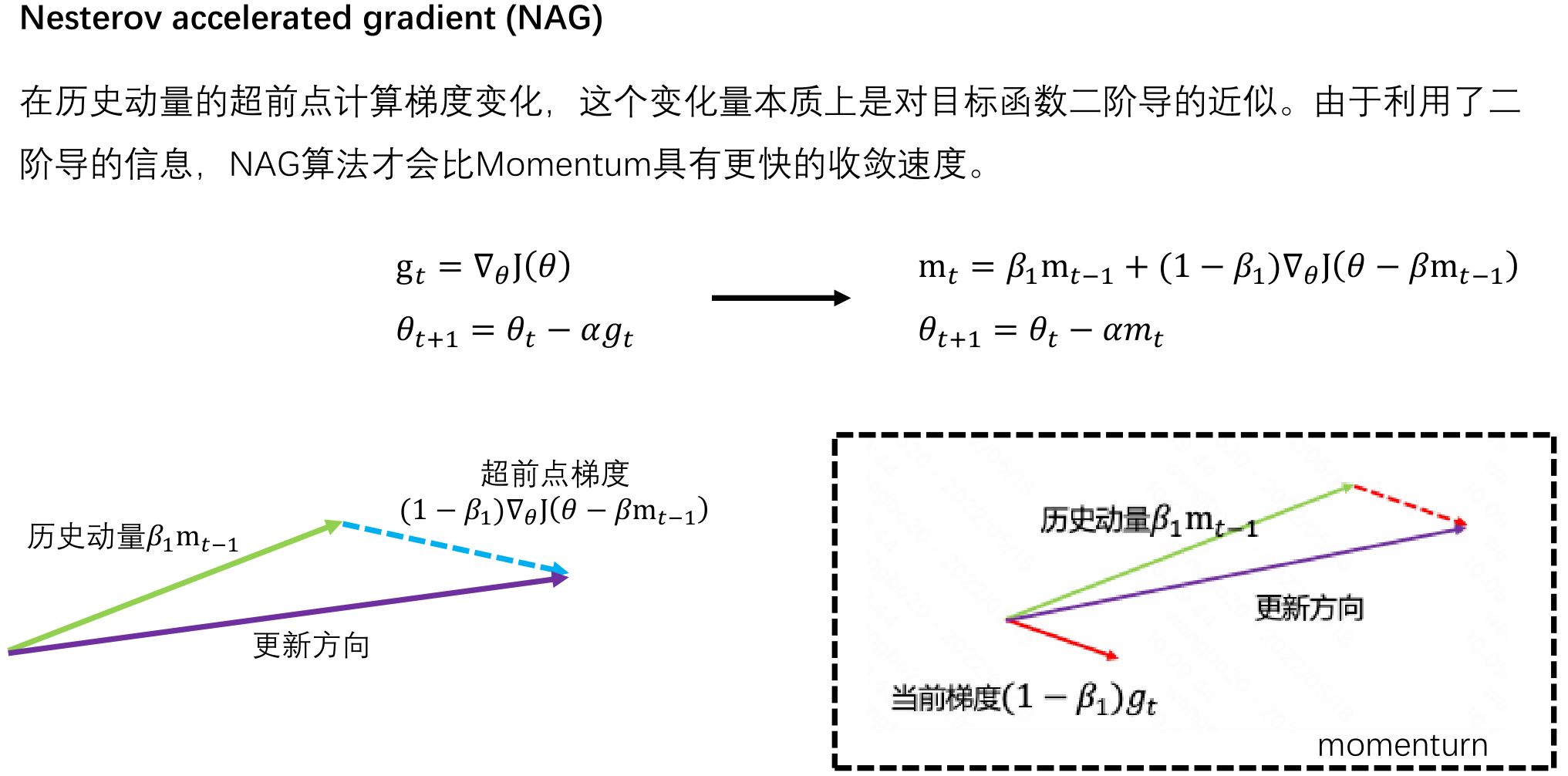
2.3 SGD with NAG
2.4 AdaGrad
2.5 RMSprop

2.6 Adam & Nadam

2.7 梯度折断
一种比较简单的启发式方法,把梯度的模限定在一个区间,当梯度的模小于或大于这个区间时就进行截断。(在训练Transformer时经常用到)
\[\mathbf{g}_t = \max(\min(\mathbf{g}_t, b), a)\]