Overview
强化学习中采用术语agent、environment和action代替controller、controlled system (or plant)和control signal,因为前者的含义更广泛。
强化学习的特征
- 探索过程
- 奖励延迟
- 时间有影响(序列数据,而非i.i.d.(独立同分布)的)
- agent的行为会影响随后得到的数据(agent的行为会改变环境)
强化学习可以取得超人的效果。
1.1 序列决策简介
1.1.1 Rewards
- 奖励是标量反馈信号
- 表明agent在第t步表现如何
- 强化学习是基于最大化奖励的:agent的目标可以描述为使期望积累的奖励最大。
使用奖励信号来描述目标的概念是强化学习最显著的特征之一。
奖励信号是用来告诉agent我们想要什么的,而不是我们想要如何达到目标。
1.1.2 Sequential decision making
- agent的目标:选择一系列行为来最大化未来总奖励
- 行为可能会产生长期影响
- 奖励可能会延迟
- 短期奖励与长期奖励的权衡
- 历史是观察、行为、奖励的序列\(H_t = O_1, R_1, A_1, \ldots, A_{t-1}, O_t, R_t\)
- 下面会发生什么与历史有关
- 状态是用于决定下面发生什么的函数\(S_t = f(H_t)\)
- 环境状态\(S_t^e = f^e(H_t)\)和agent状态\(S_t^a = f^a(H_t)\)
- 完全可观性:agent可以直接观察到环境状态,被建模为马尔可夫决策过程(MDP)\(O_t = S_t^e = S_t^a\)
- 部分可观性:agent无法直接观察到环境状态,被建模为部分可观马尔可夫决策过程(POMDP)
1.1.3 RL angent的主要成分
一个RL angent可能包括以下一个或多个成分:
- 策略:agent的行为函数
- 价值函数:评估当前状态或行为
- 模型:agent对环境的理解
Policy
策略是agent的行为模型,是从输入状态/观察到行为的映射
有两种策略:
- Stochastic policy(随机策略):概率样本\(\pi (a \vert s) = P[A_t = a \vert S_t = s]\)
- Deterministic policy(确定性策略):\(a^* = \mathop{argmax}_a \pi (a \vert s)\)
Value function
值函数:特定策略\(\pi\)下延迟奖励的预期折现
折扣因子可以权衡即时奖励 vs 延迟奖励,用于量化状态与行为的好/坏 \(v_{\pi} \doteq \mathbb{E}_{\pi} [G_t \vert S_t=s] = \mathbb{E}_{\pi} \bigg[ \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} \vert S_t = s \bigg] \ , \forall s \in S\)
Q-function(可用于在行为中进行选择) \(q_{\pi}(s,a) \doteq \mathbb{E}_{\pi} [G_t \vert S_t=s, A_t = a] = \mathbb{E}_{\pi} \bigg[ \sum_{k=0}^{\infty} \gamma^k R_{t+k+1} \vert S_t = s, A_t = a \bigg]\)
Model
模型用于预测环境下一步会做什么
- 预测下一步状态:\(P_{ss'}^a = \mathbb{P} [ S_{t+1} = s' \vert S_t = s, A_t = a ]\)
- 预测下一步奖励:\(P_{s}^a = \mathbb{E} [ R_{t+1} = s' \vert S_t = s, A_t = a ]\)
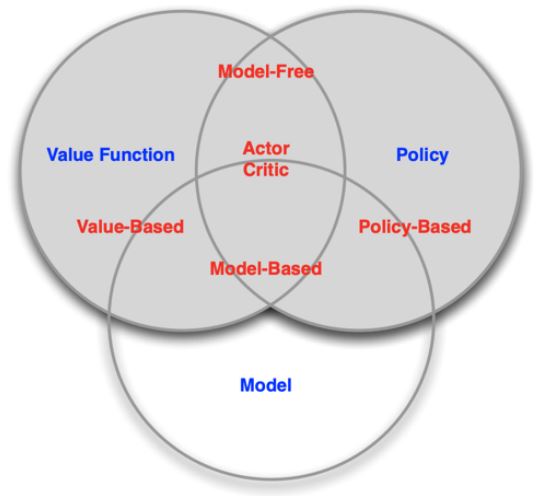
Agent的分类
根据agent学习的内容分类
- Value-based agent
显式:值函数
隐式:策略(可以从价值函数导出策略) - Policy-based agent
显式:策略
没有值函数 - Actor-Critic agent
显式:策略和值函数
根据是否有模型分类
- Model-based
显式:模型
可能有/没有策略和/或值函数 - Model-free
显式:值函数和/或策略函数
没有模型
1.2 序列决策中的两大问题
- Planning
- 给定环境如何工作的模型
- 计算如何行动能最大化期望回报,且没有外部互动
- Reinforcement learning
- agent不知道世界如何运作
- 通过与世界交互来学习世界如何运作
- agent会改善策略(也包括规划)
1.3 Exploration and Exploitation
Agent只能经历尝试的行为发生的后果。
一个RL Agent应如何平衡自己的行为?
- Exploration:尝试可能使agent在未来做出更好决策的新事物
- Exploitation:根据过去的经验,选择预期会产生良好回报的行动
通常会存在探索与利用的权衡
- 为了探索和了解可能更好的政策,可能不得不牺牲奖励
