Brief Talk on ML
The Pokémon Digimon Classifier

以Pokémon vs. Digimon作为案例。我们希望找到一个函数,可以实现
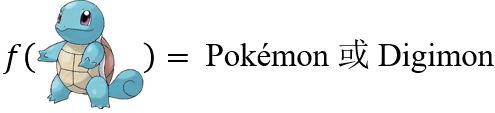
即确定一个带有未知参数的函数(基于领域知识)。
Observation
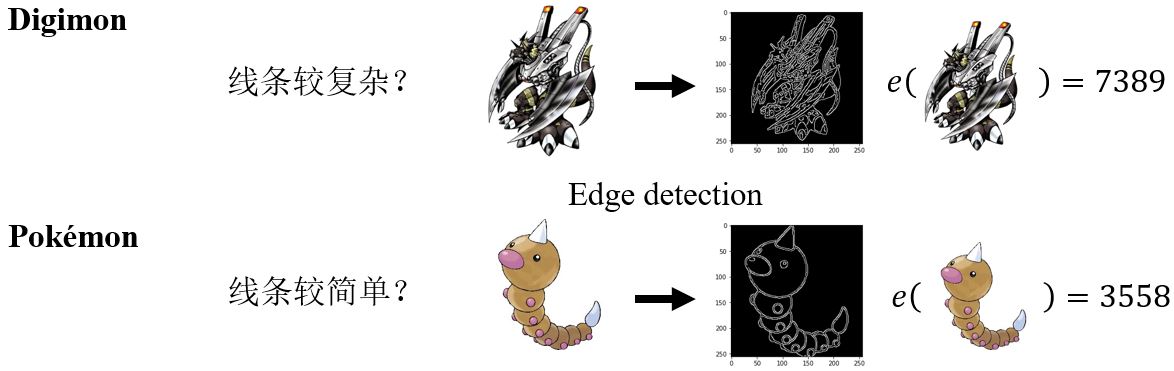
Function with Unknown Parameters
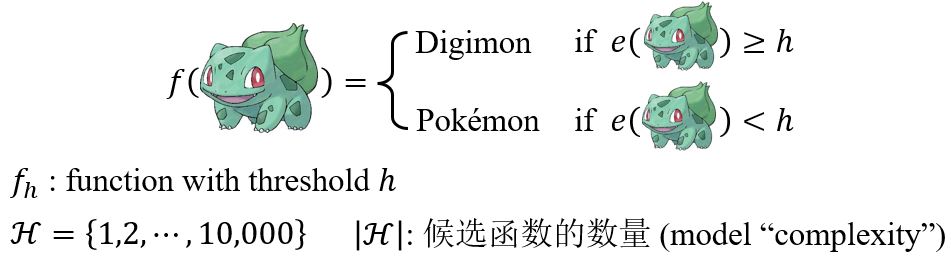
Loss of a function (given data)

Training Examples
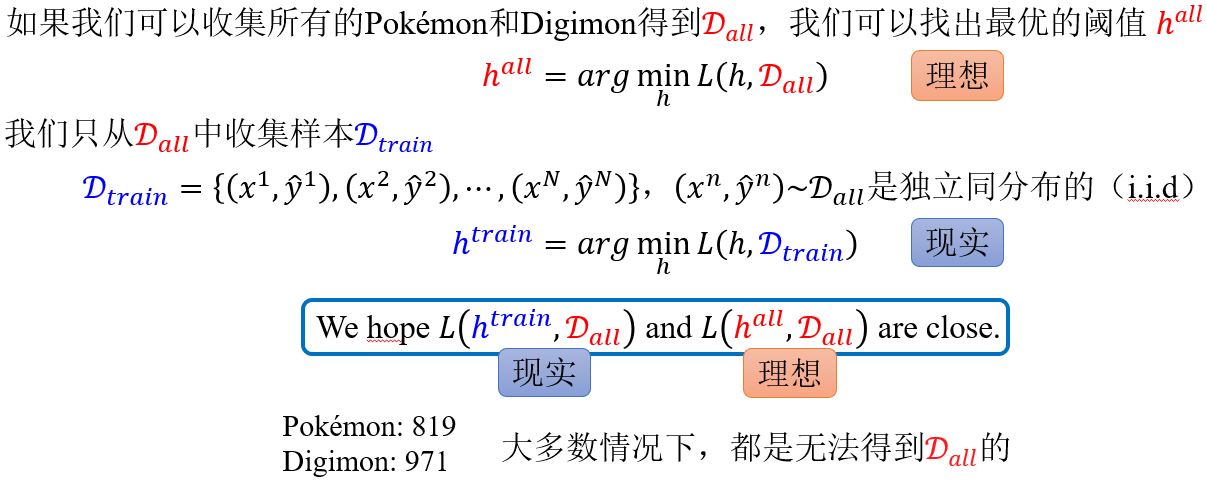
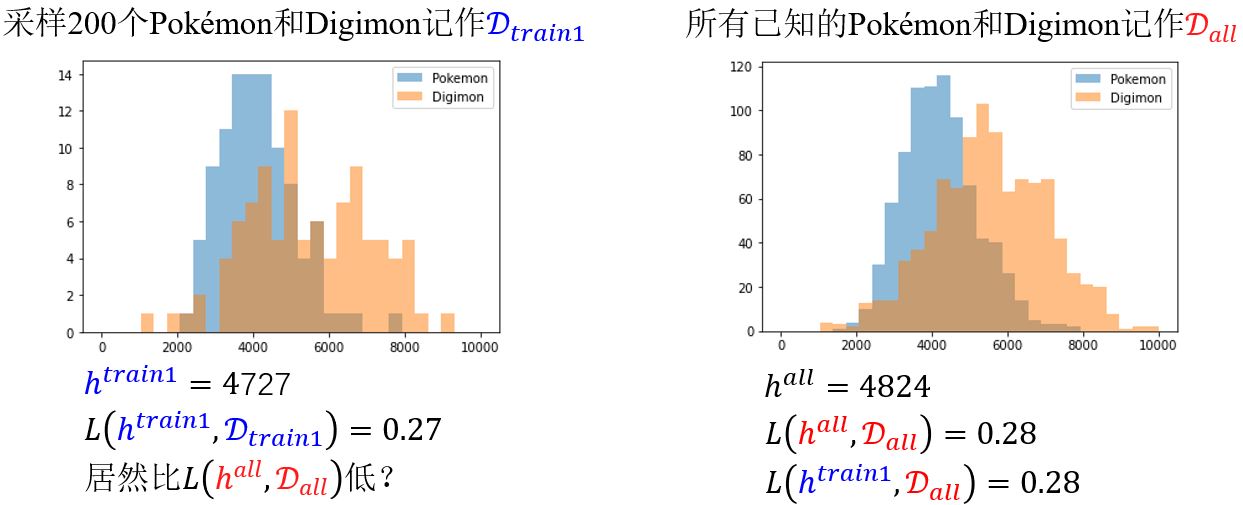
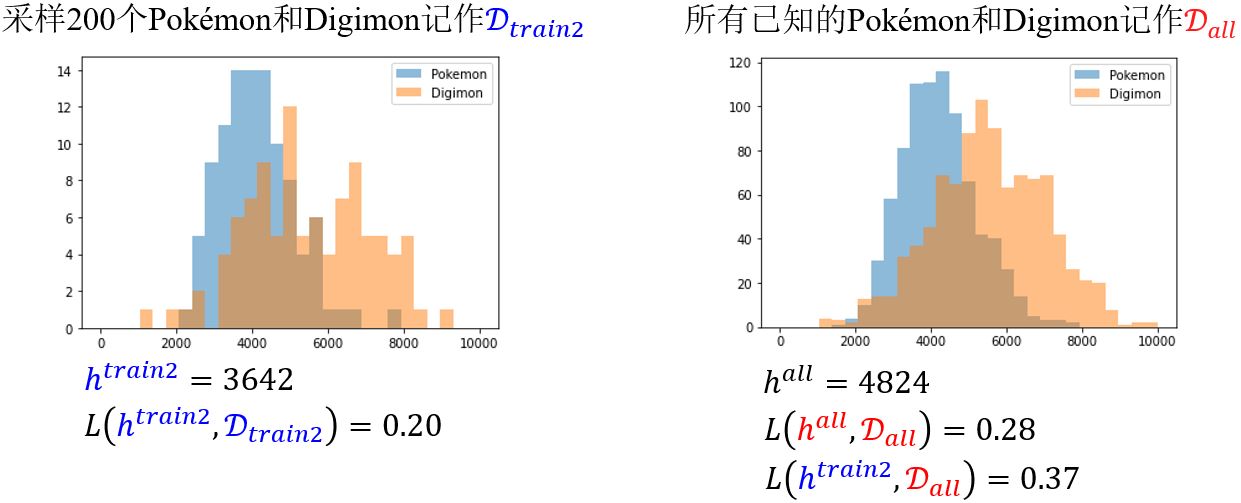
\(L(\color{red}{h^{all}, D_{all}} \color{black}{)}\)只有在\(D_{all}\)上是最小的,所以\(L(\color{blue}{h^{train}, D_{train}} \color{black}{)}\)是可以比\(L(\color{red}{h^{all}, D_{all}} \color{black}{)}\)小的。
What do we want?

所以,我们希望采样到good \(\color{blue}{D_{train}}\)满足
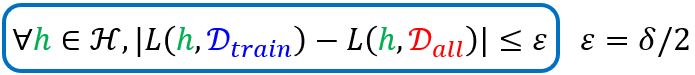
那么到底有多大概率会采样到bad \(\color{blue}{D_{train}}\)呢?
Probability of failure
补充
以下讨论very general,是model-agnostic的,无需关于data distribution的假设,可以用任意的loss function。
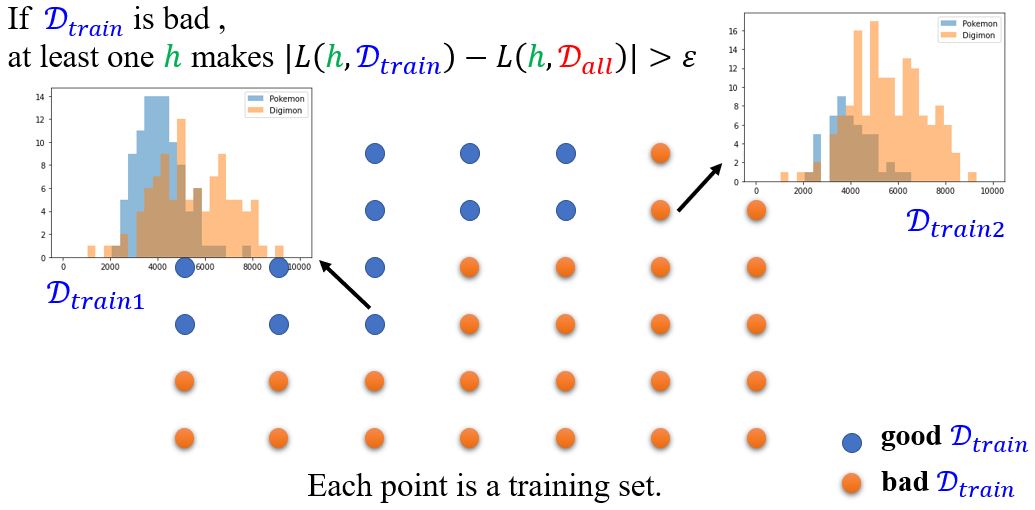
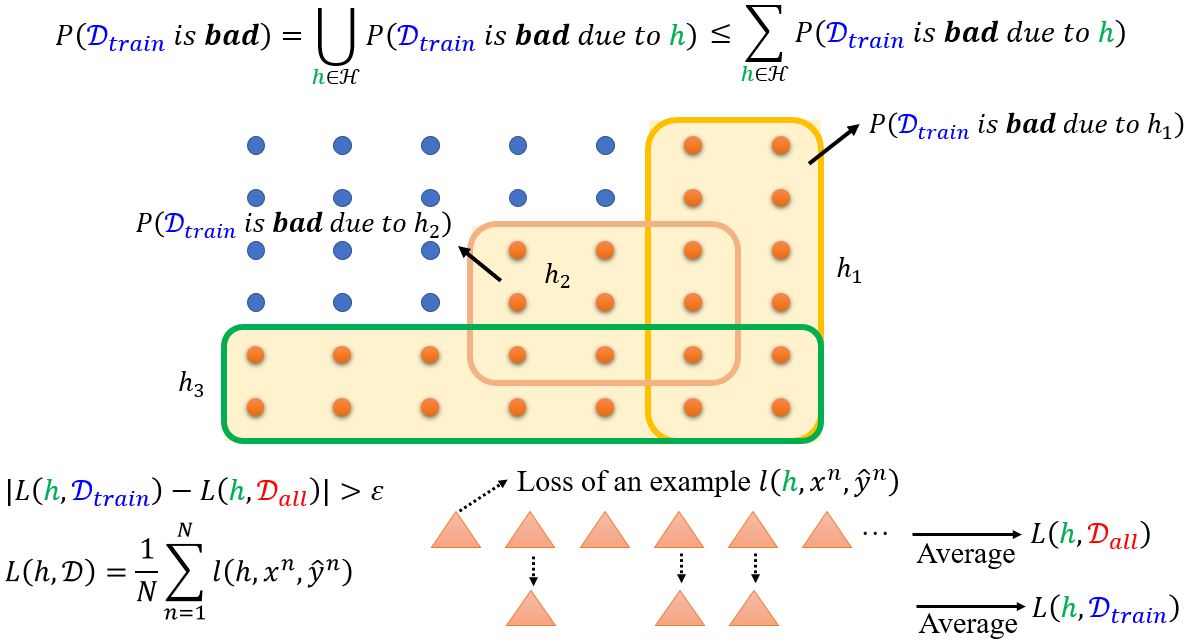

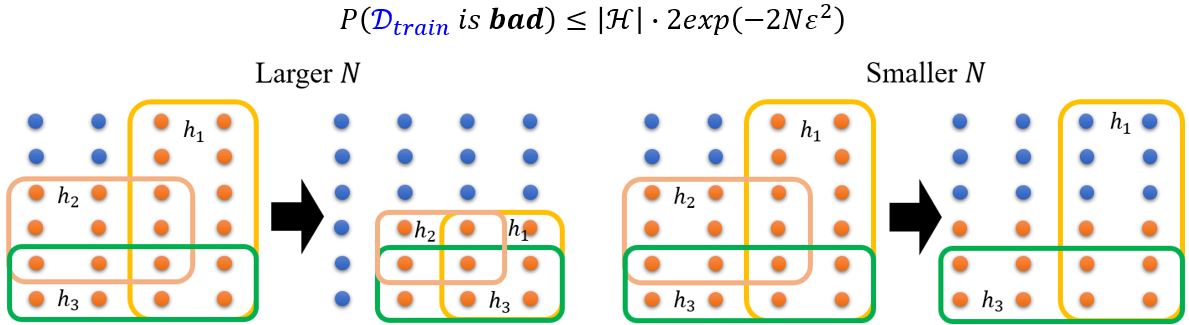
例:
Model Complexity
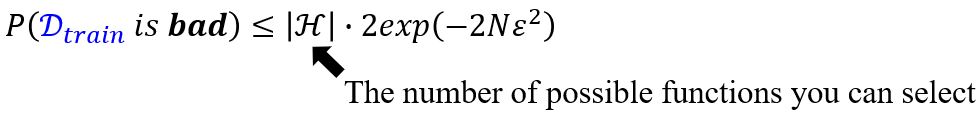
如果参数是连续的呢?
Answer 1: 计算机中所有计算都是离散的。
Answer 2: VC-dimension (not this course)

Tradeoff of Model Complexity
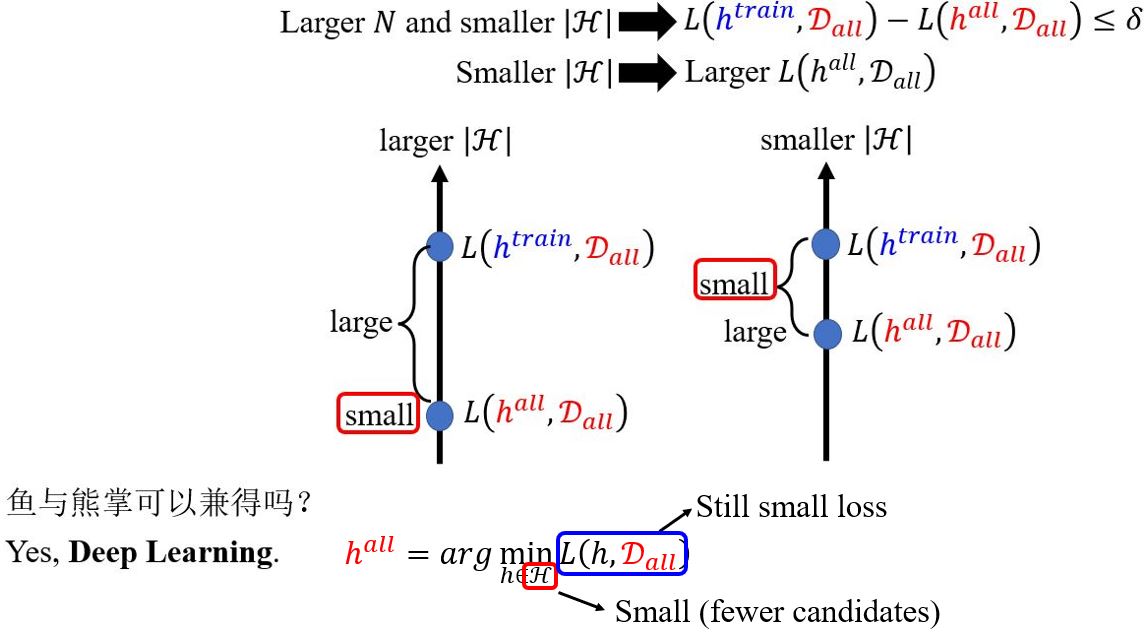
Why Deep?
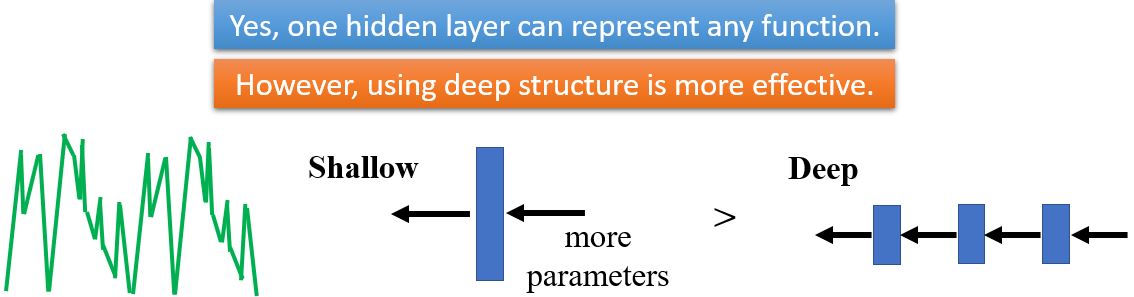
Review: Why hidden layer?
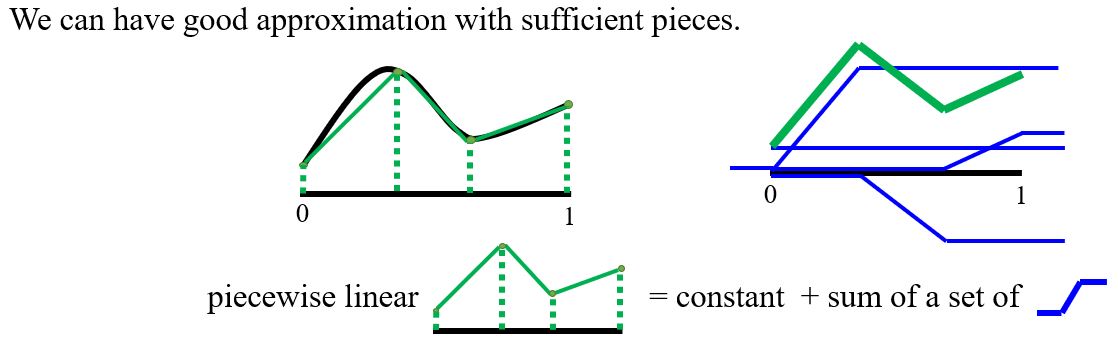
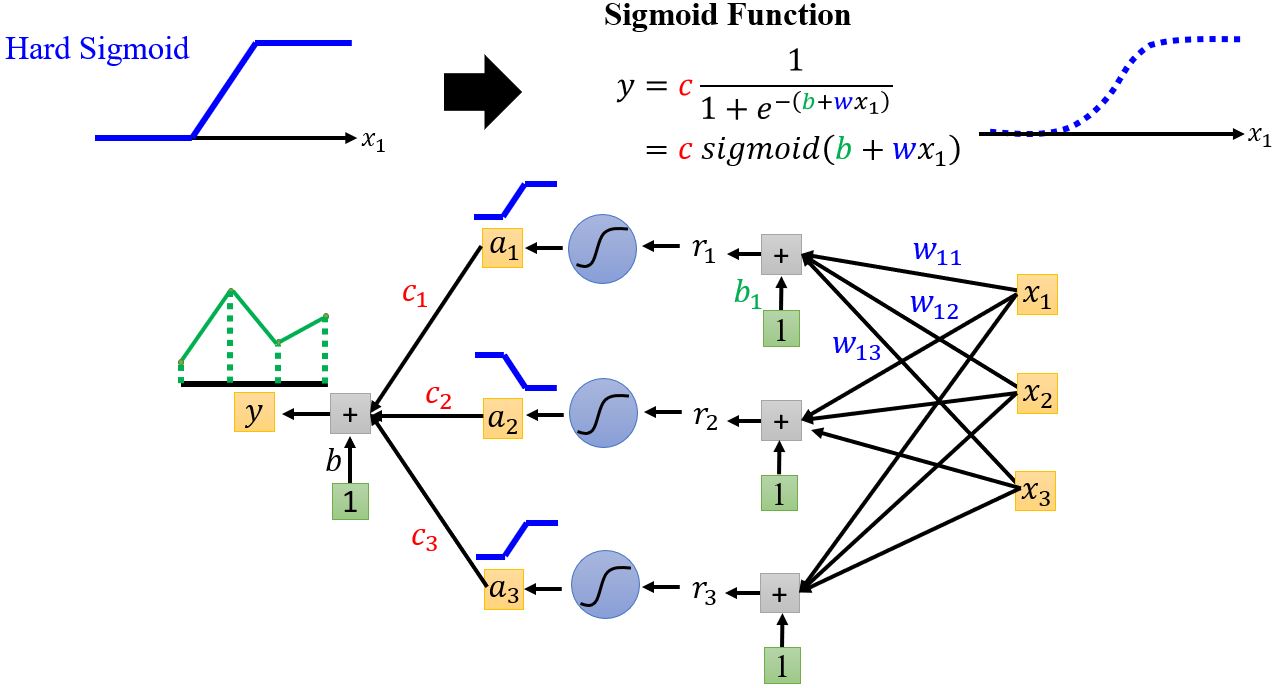
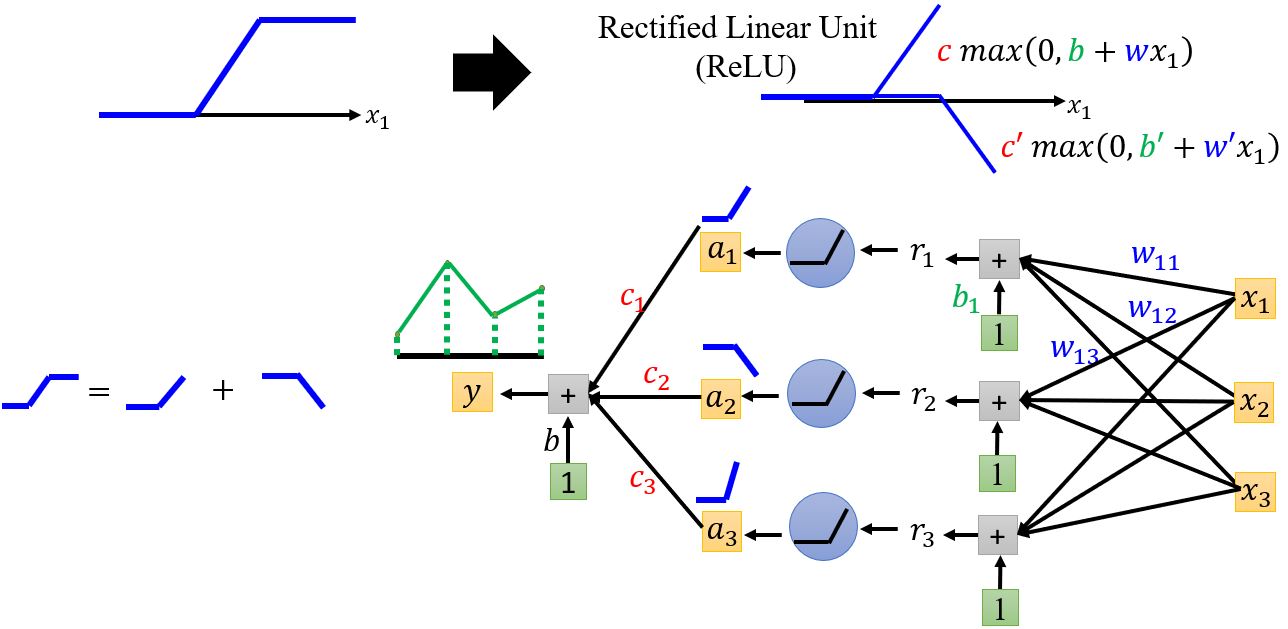
Piecewise linear
Hard Sigmoid → Sigmoid function
Hard Sigmoid → ReLU
提示
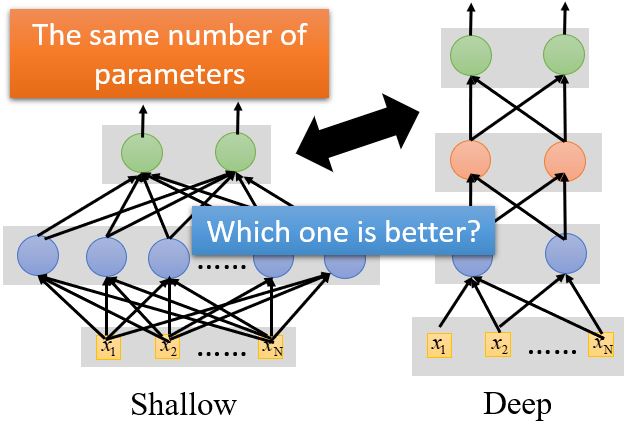
为什么我们想要”Deep” network,而不是”Fat” network?
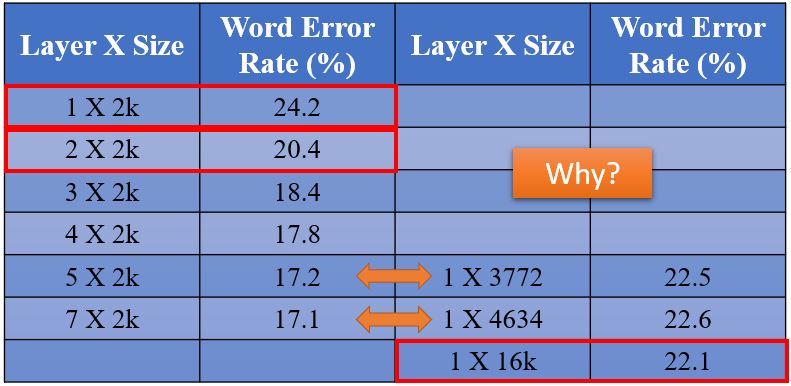
Deep is better?