Actor-Critic
Review-Policy Gradient
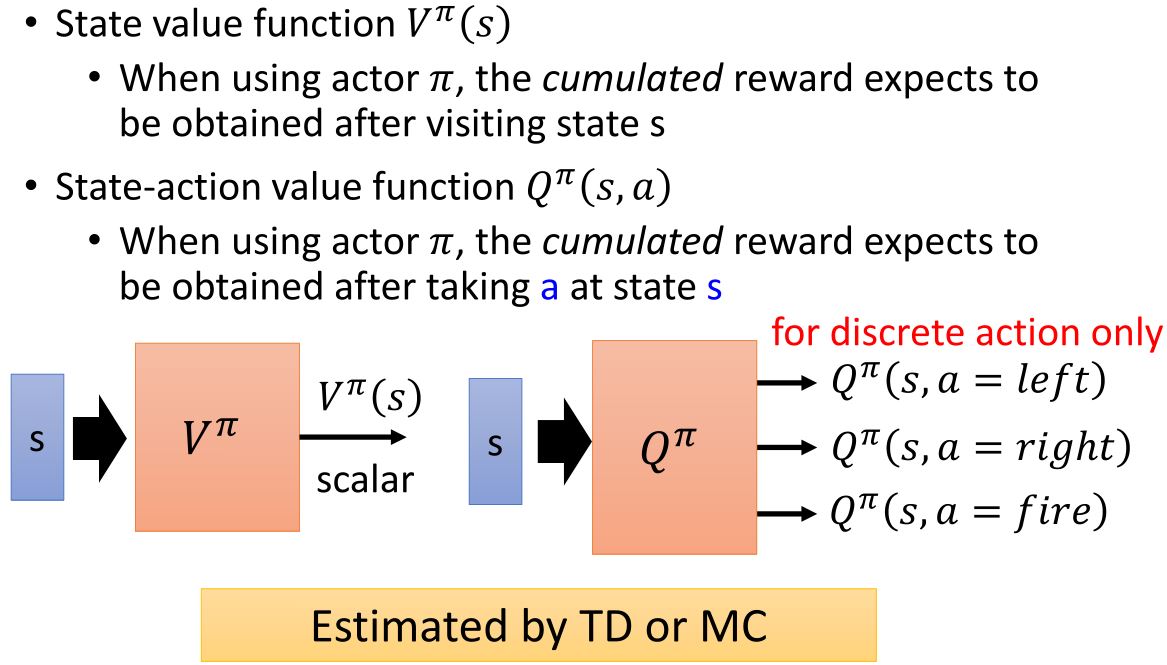
Review-Q-Learning
Actor-Critic
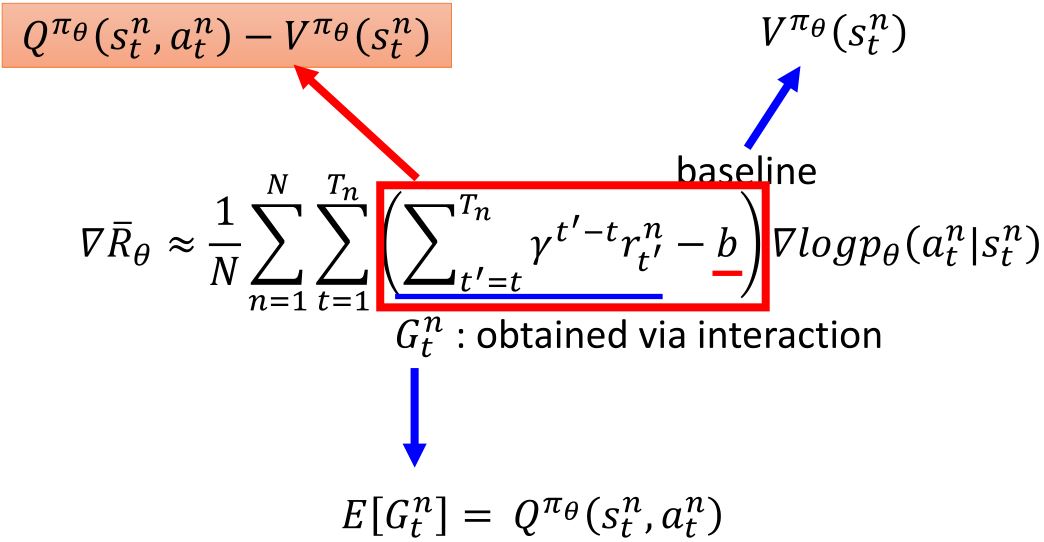
4.1 Advantage Actor-Critic
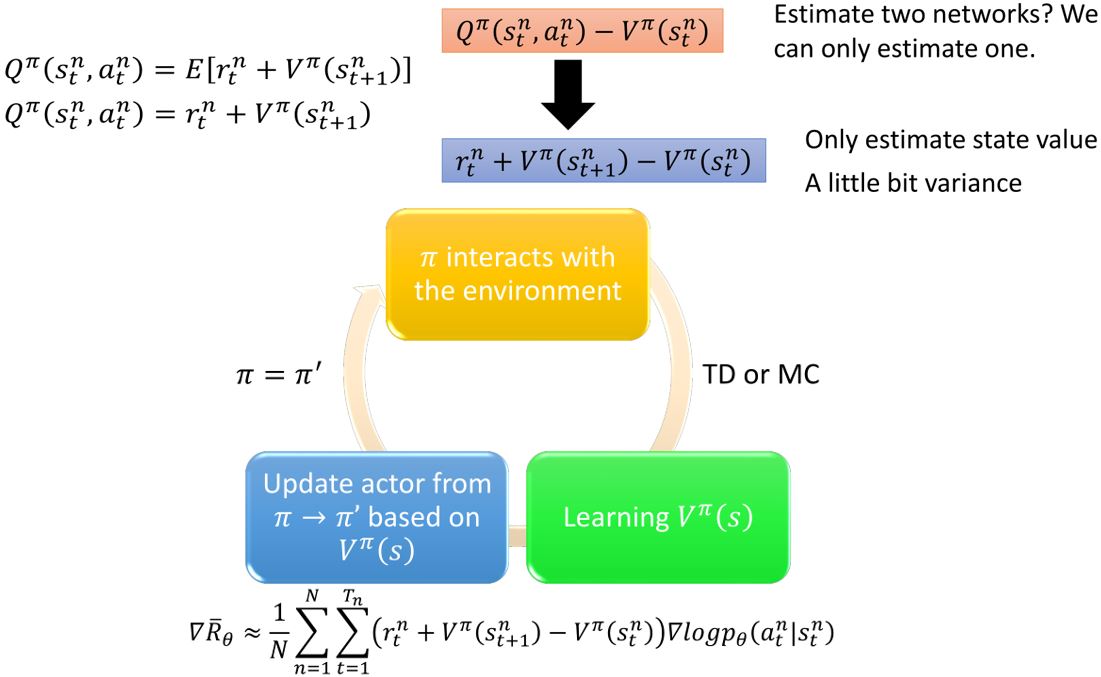
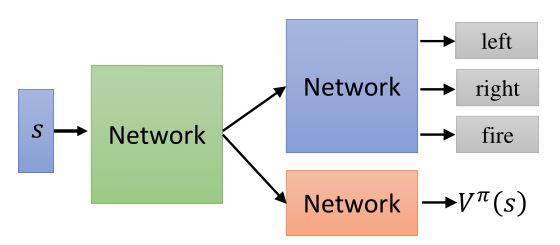
Tips:
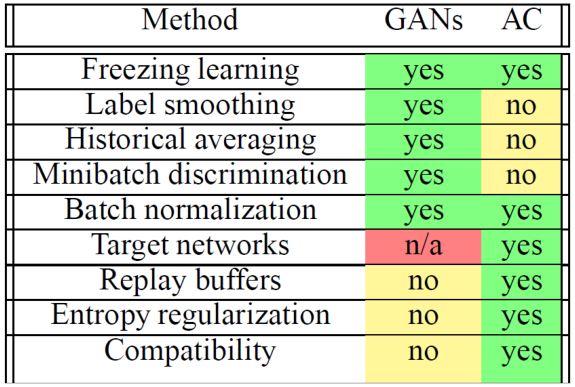
- actor \(\pi(s)\)和critic \(V^{\pi}(s)\)的参数可以共享
- 用输出熵作为\(\pi(s)\)的正则化
倾向于更大的熵 \(\rightarrow\) exploration
4.2 Asynchronous Advantage Actor-Critic (A3C)
在A2C的基础上,利用多个worker来收集经验。
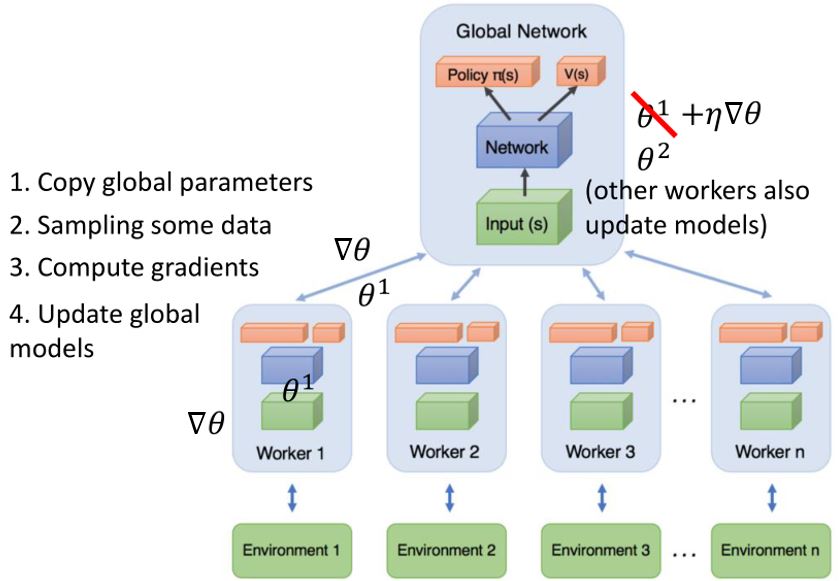
4.3 Pathwise Derivative Policy Gradient
David Silver, Guy Lever, Nicolas Heess, Thomas Degris, Daan Wierstra, Martin Riedmiller, "Deterministic Policy Gradient Algorithms", ICML, 2014.
Timothy P . Lillicrap, Jonathan J. Hunt, Alexander Pritzel, Nicolas Heess, Tom Erez, Yuval Tassa, David Silver, Daan Wierstra, "CONTINUOUS CONTROL WITH DEEP REINFORCEMENT LEARNING", ICLR, 2016.
4.3.1 Another way to use critic
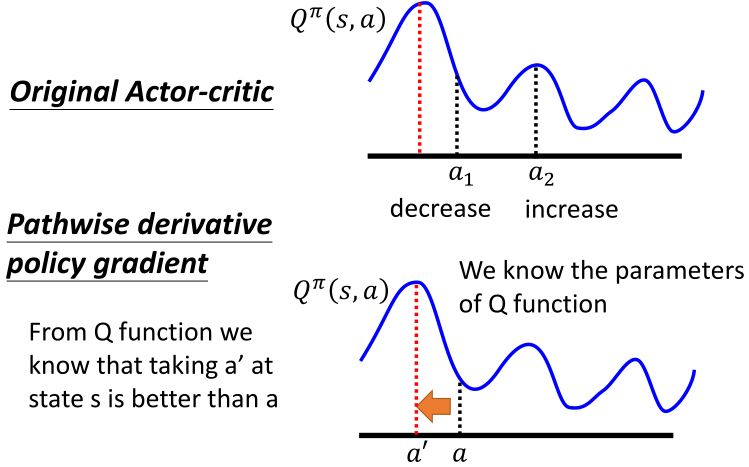

4.3.2 PDPG
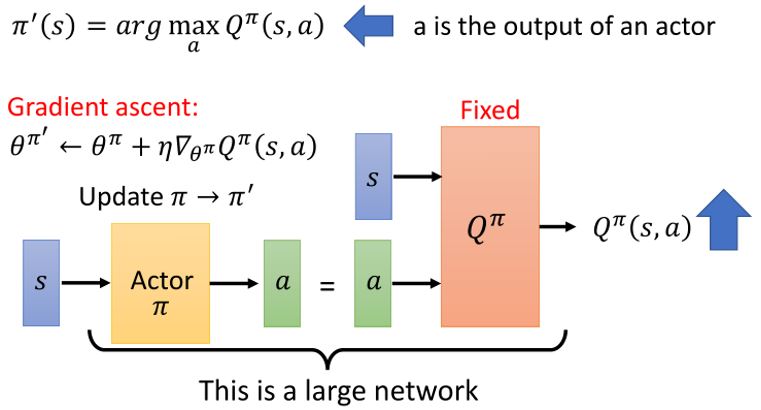
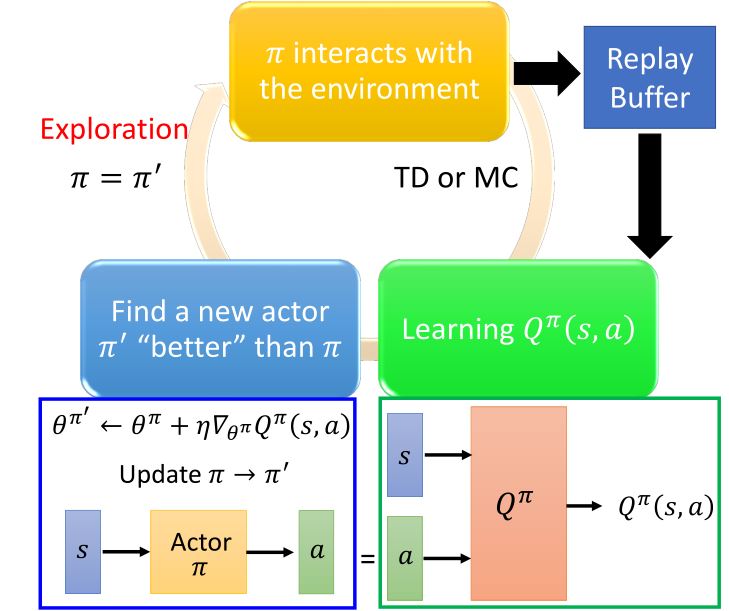

4.3.3 Connection with GAN