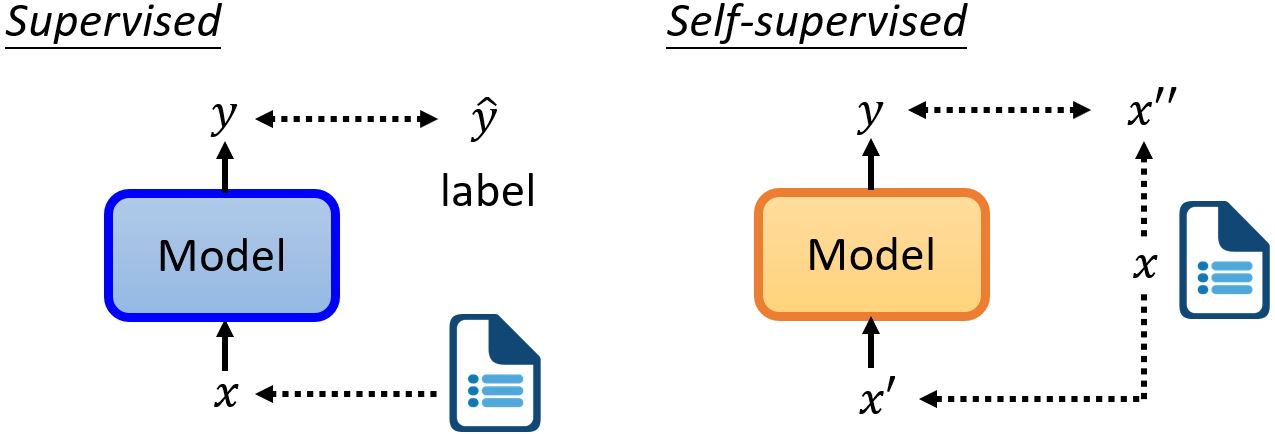
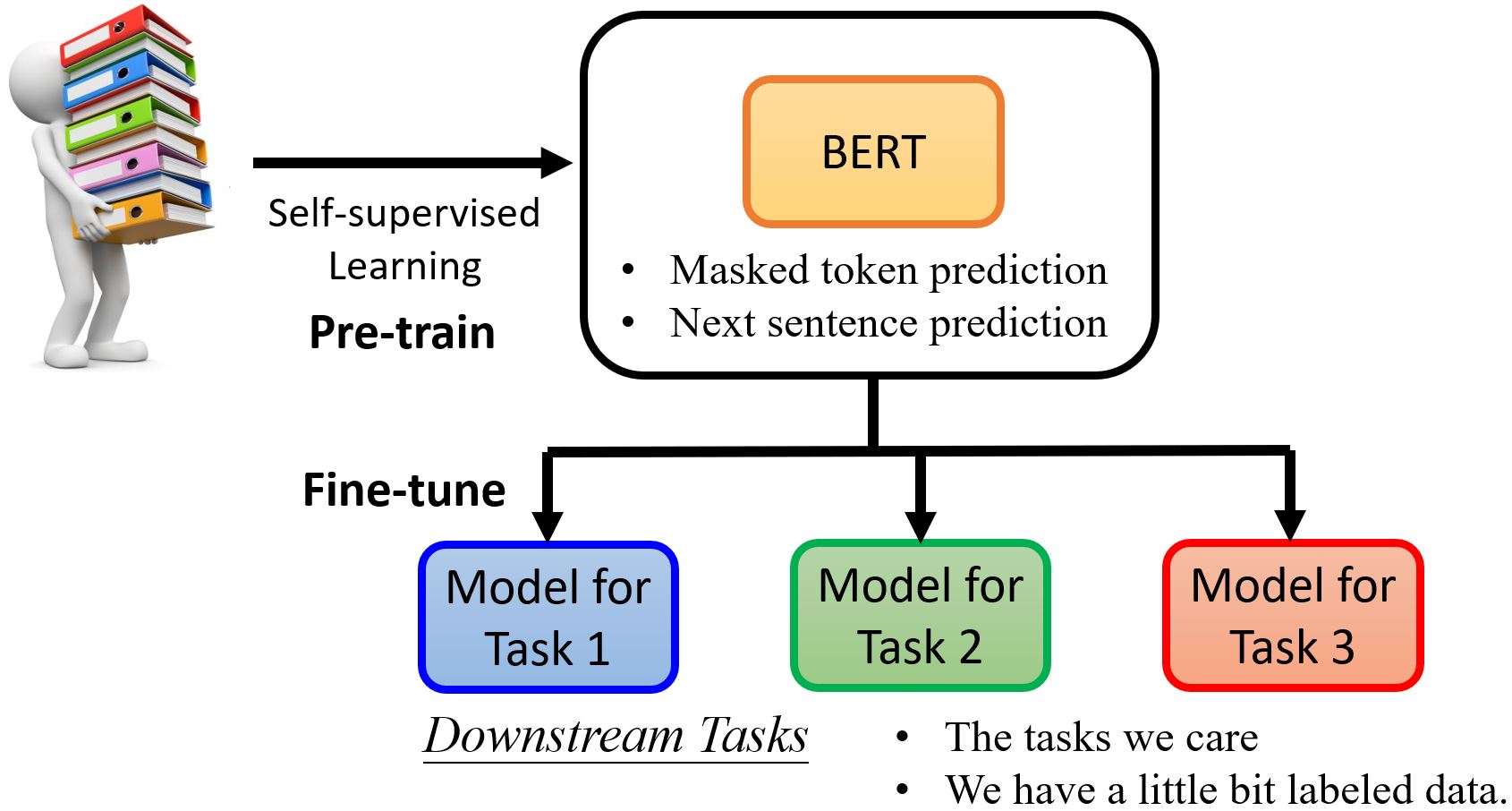
Self-Supervised Learning
BERT的参数量为340M,模型在变得越来越大。
| ELMo | BERT | GPT-2 | Megatron | T5 | Turing NLG | GPT-3 | Switch Transformer |
|---|---|---|---|---|---|---|---|
| 94M | 340M | 1542M | 8D | 11B | 17B | 175B | 1.6T |
7.1 Self-Supervised Learning
7.2 BERT
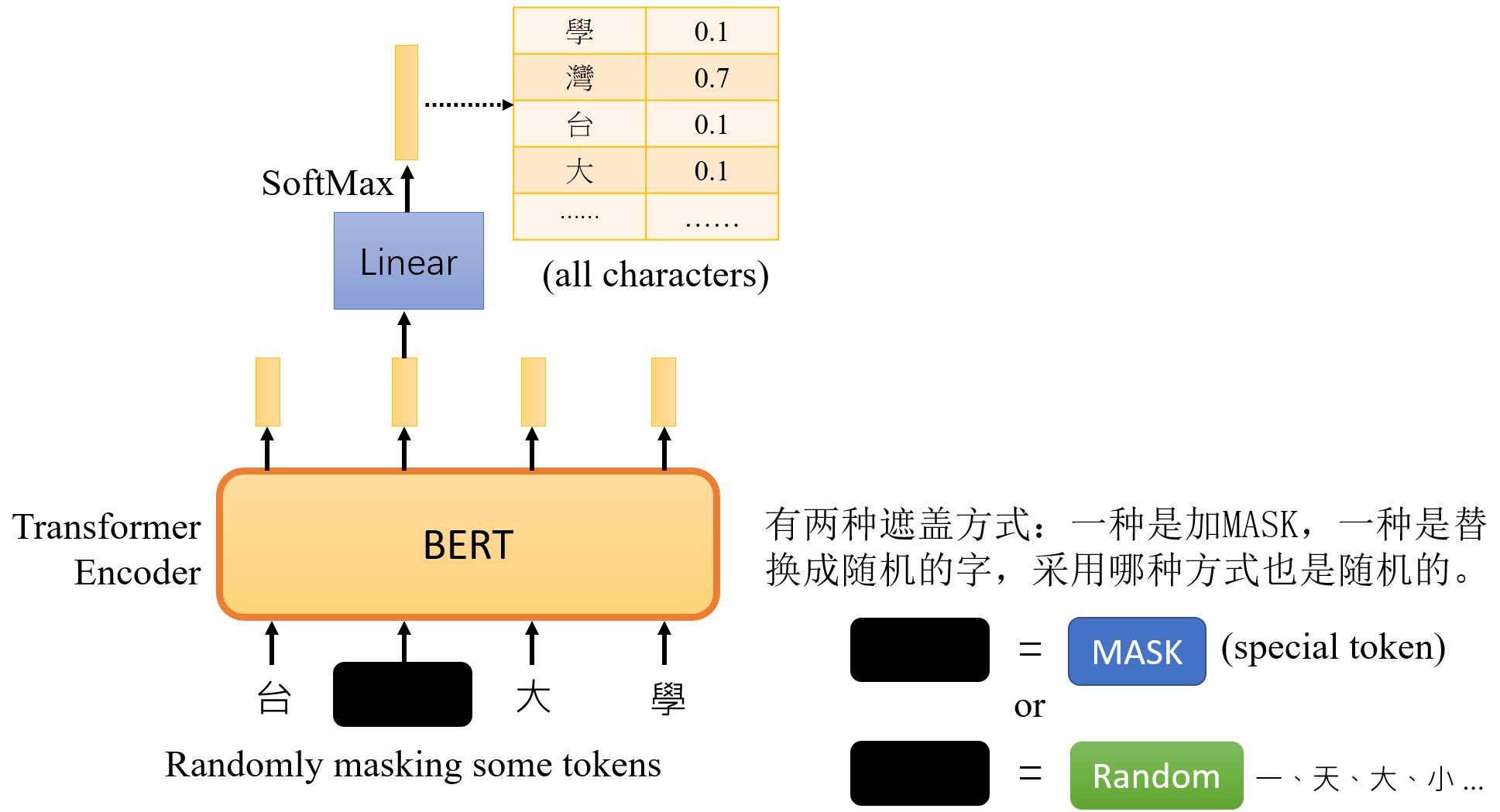
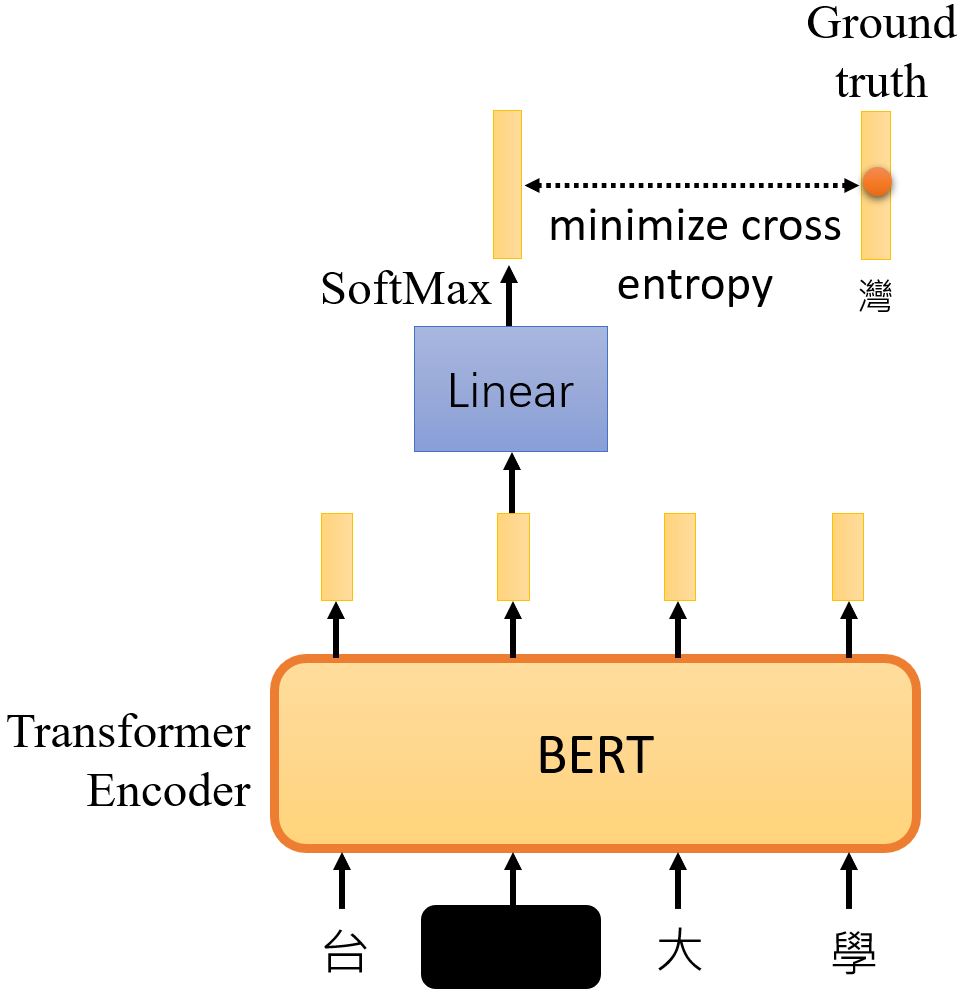
7.2.1 Masking Input
7.2.2 Next Sentence Prediction
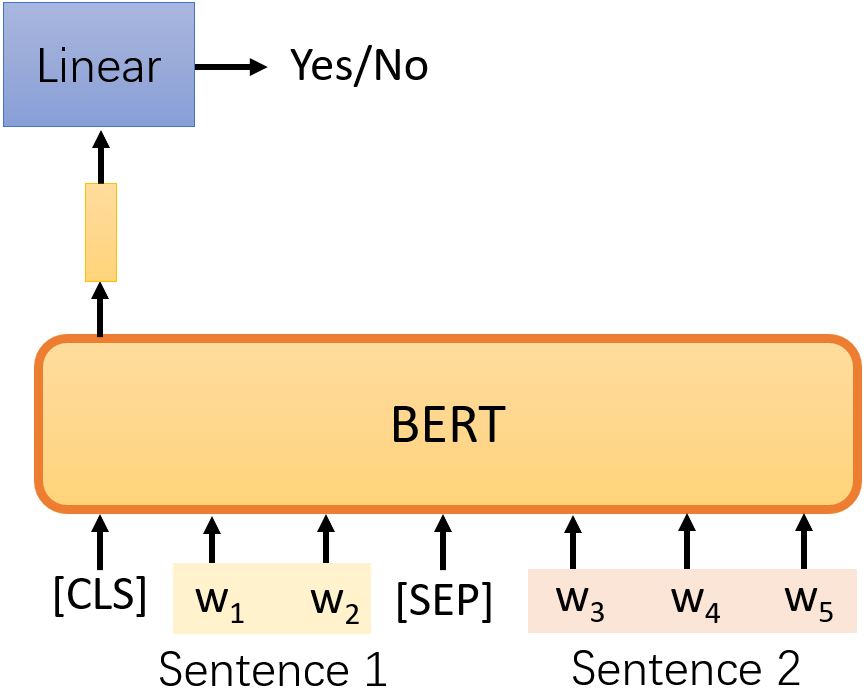
取两句话中间用[SEP]表示分隔,并在最前面加一个特殊符号[CLS]。将整个序列丢到 BERT(Transformer encoder)中得到序列,只取[CLS]所对应的输出,将其乘上一个线性变换,完成一个二元分类问题,预测两句话是否相接。
该方法现在已被证明对BERT后续的任务没有太大帮助。RoBERTa: A Robustly Optimized BERT Pretraining Approach 这可能是因为这个任务太简单了,所以对于BERT来说没有学到太多。另一种更有用的方法:SOP (Sentence order predicion) 被用于ALBERT: A Lite BERT for Self-supervised Learning of Language Representations。
7.2.3 Fine-tune
GLUE (General Language Understanding Evaluation)
- Corpus of Linguistic Acceptability (CoLA)
- Stanford Sentiment Treebank (SST-2)
- Microsoft Research Paraphrase Corpus (MRPC)
- Quora Question Pairs (QQP)
- Semantic Textual Similarity Benchmark (STS-B)
- Multi-Genre Natural Language Inference (MNLI)
- Question-answering NLI (QNLI)
- Recognizing Textual Entailment (RTE)
- Winograd NLI (WNLI)
GLUE也有中文版本。

7.2.4 How to use BERT
Case 1
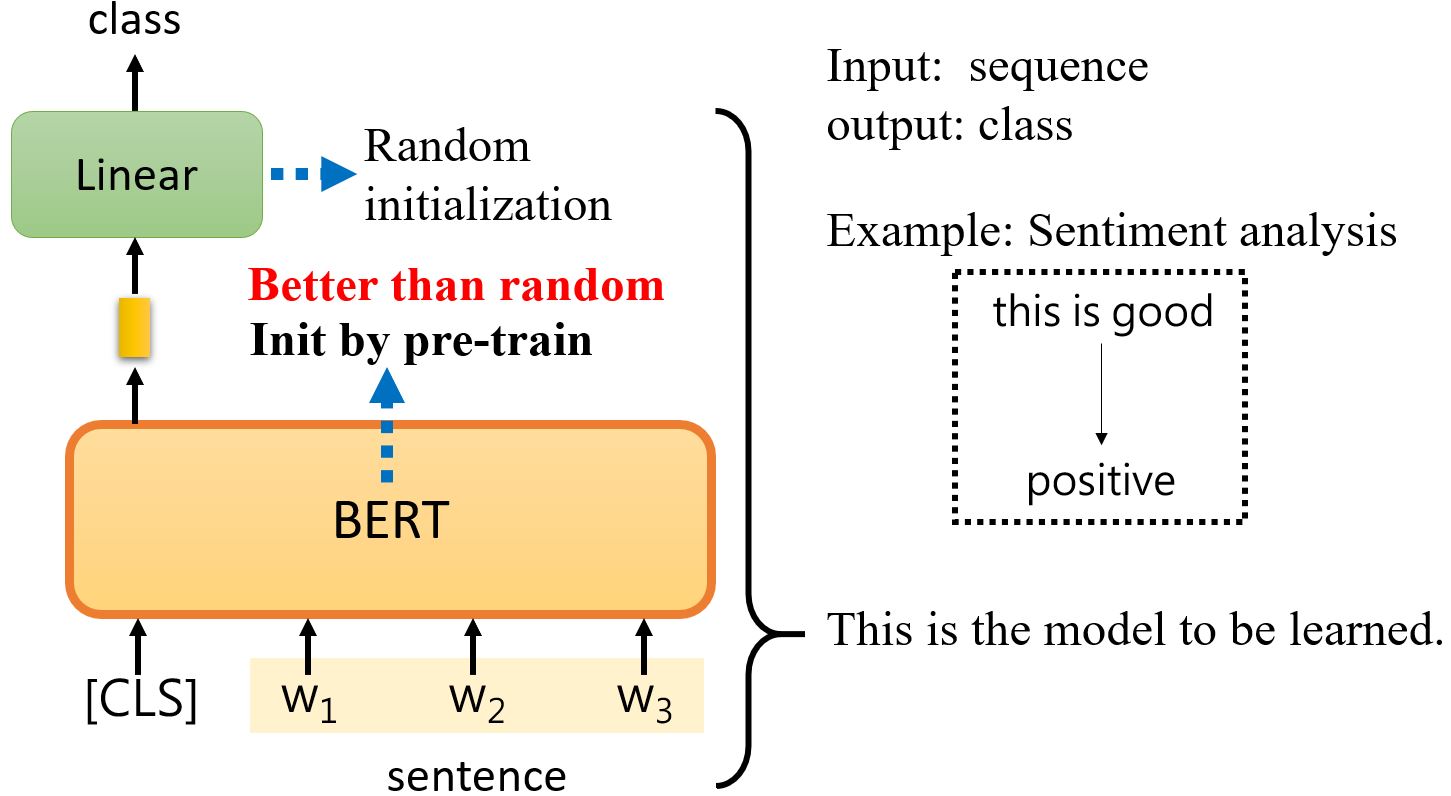
Case 2
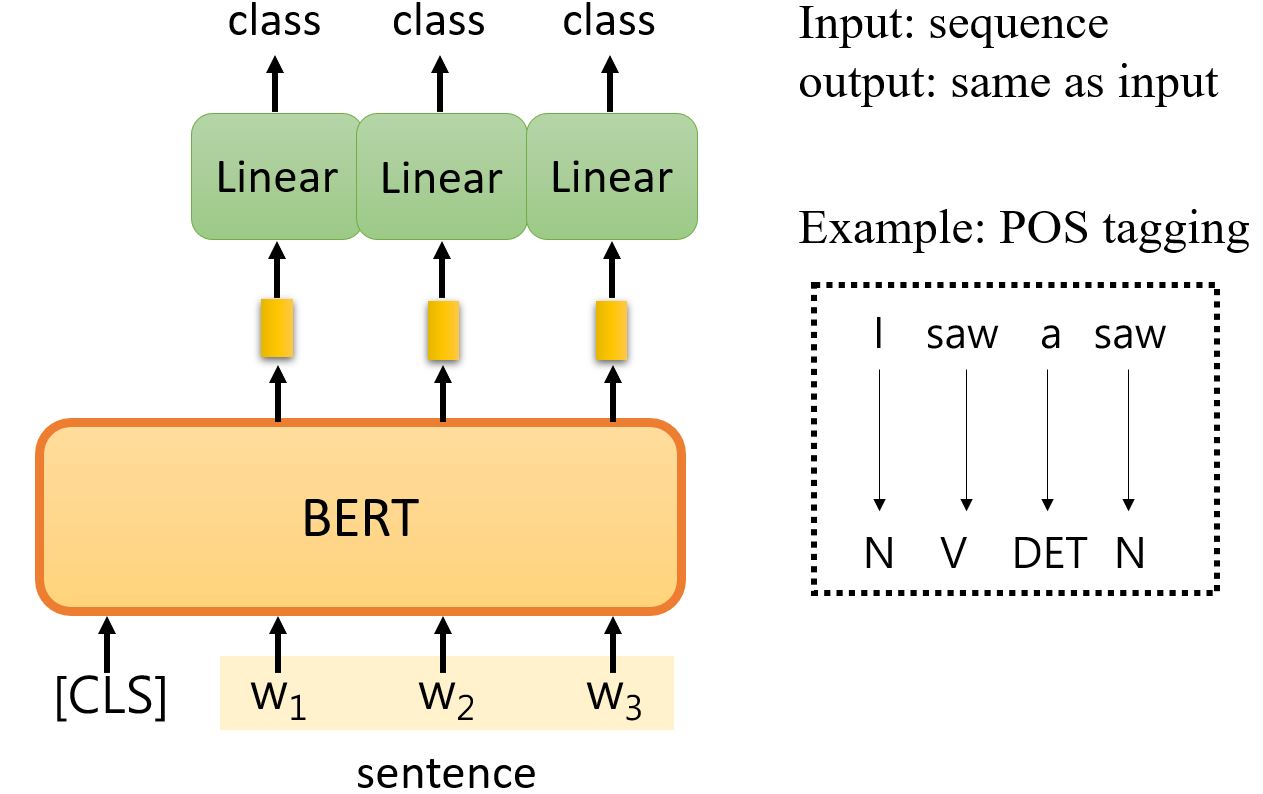
Case 3
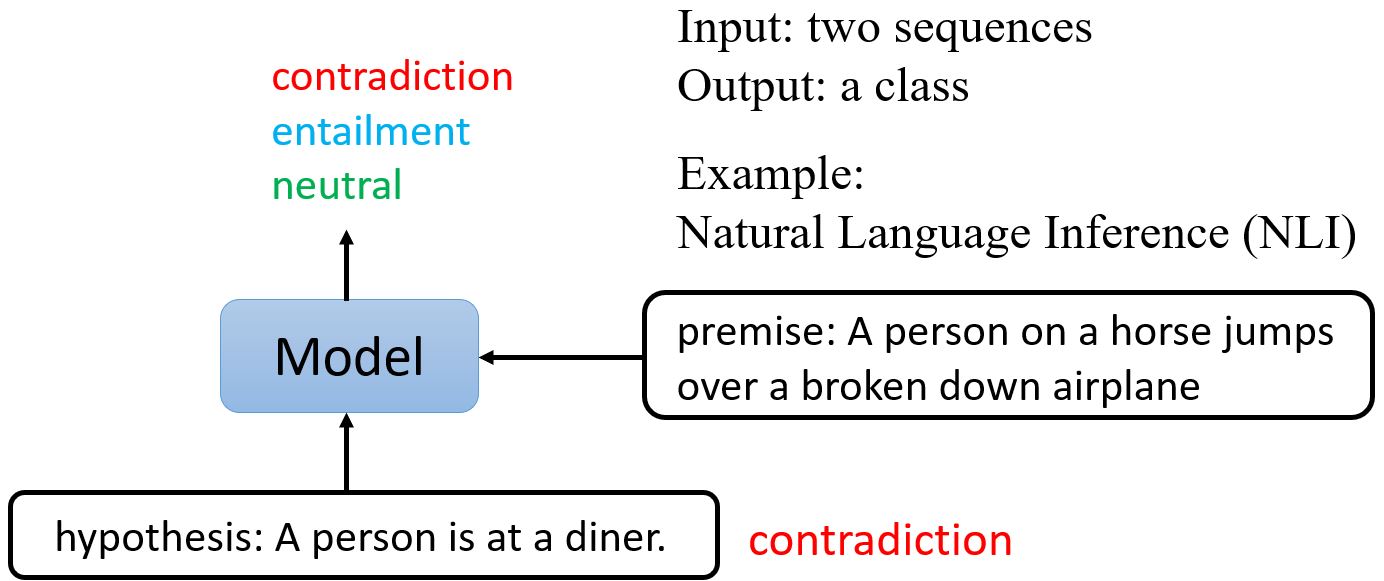
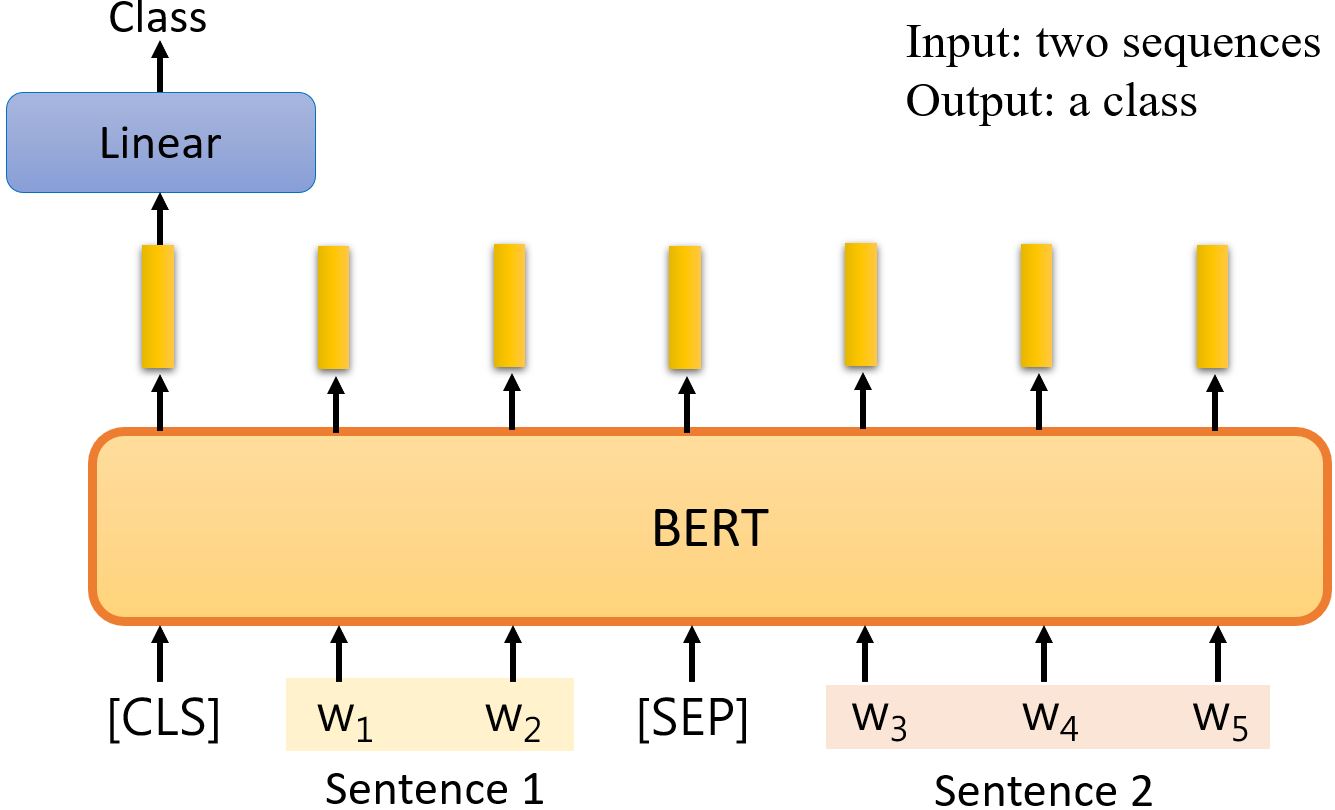
Case 4

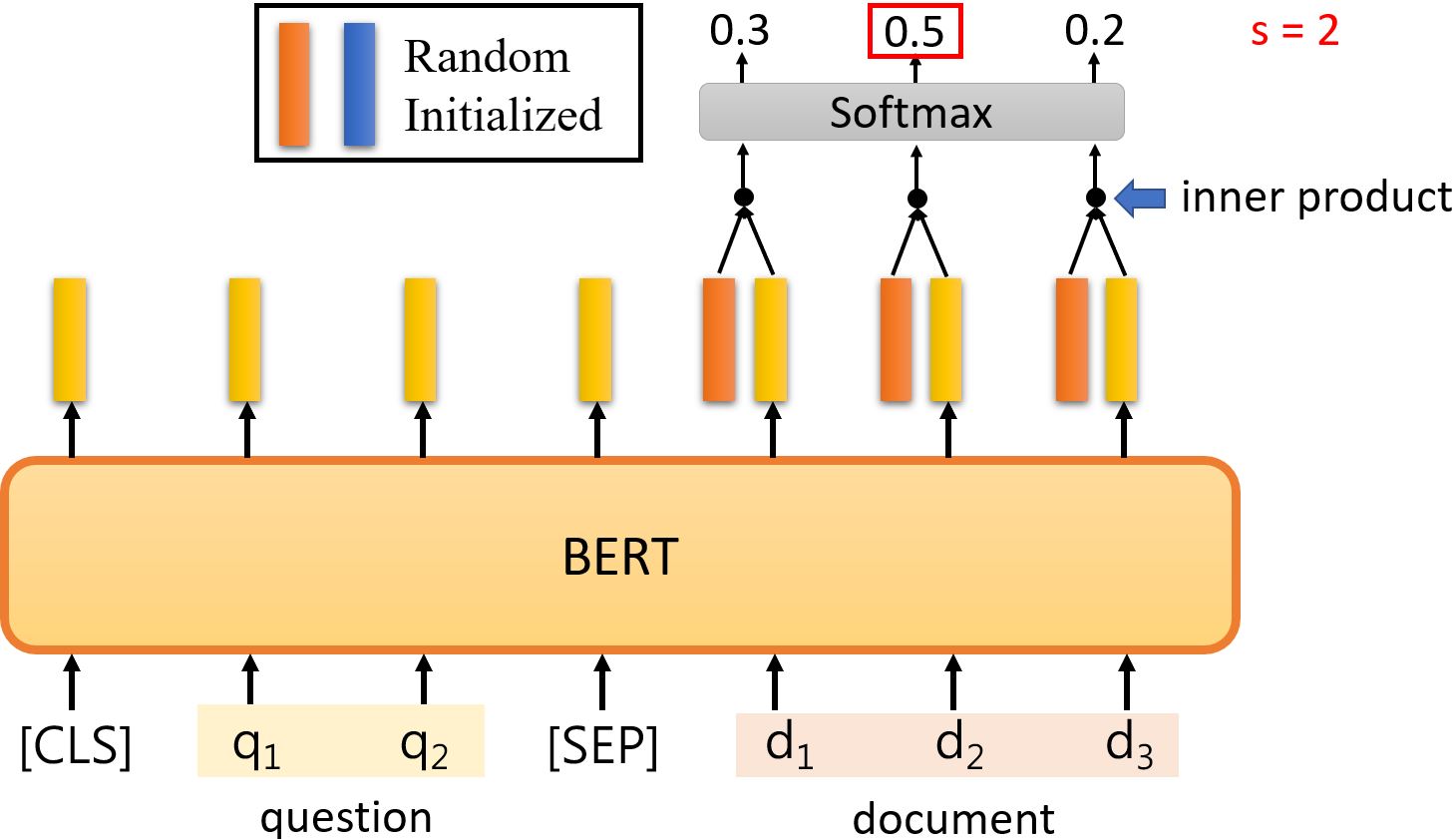
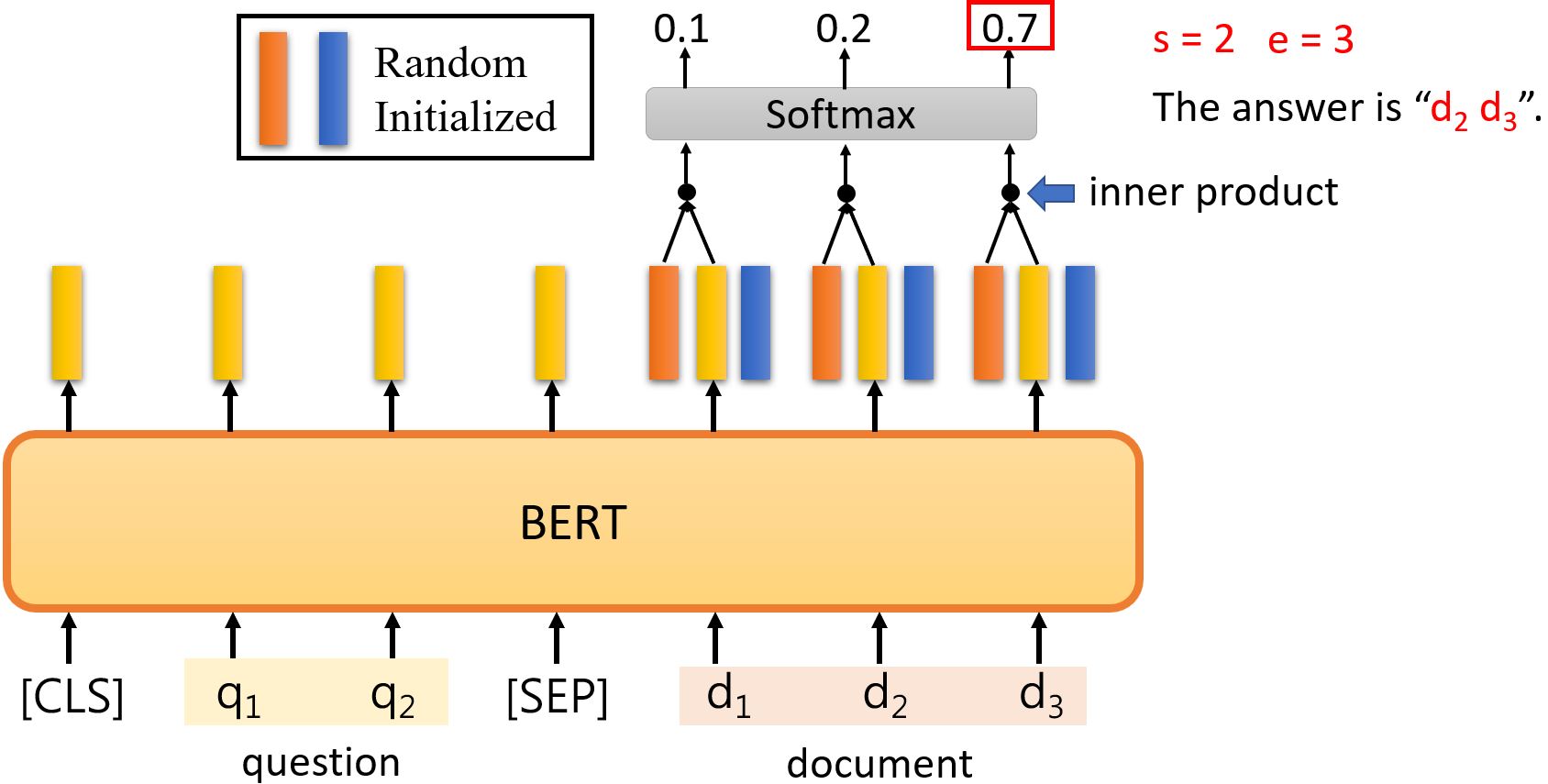
补充
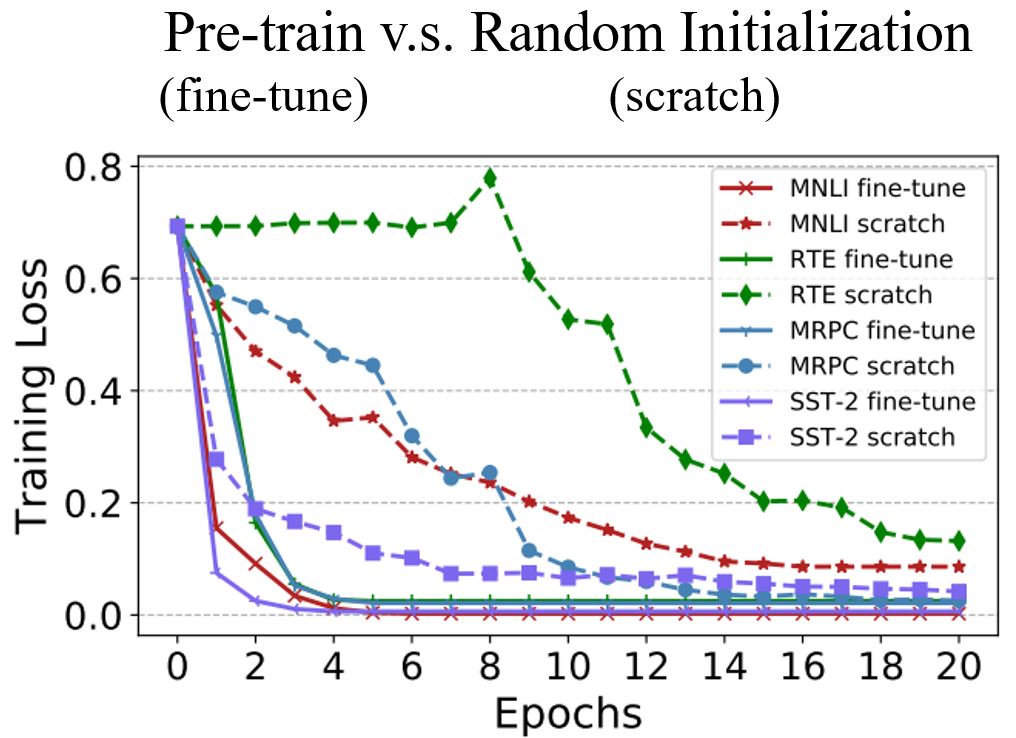
训练BERT非常有挑战性!
训练数据超过了3亿个单词,是哈利波特全集的3000倍。
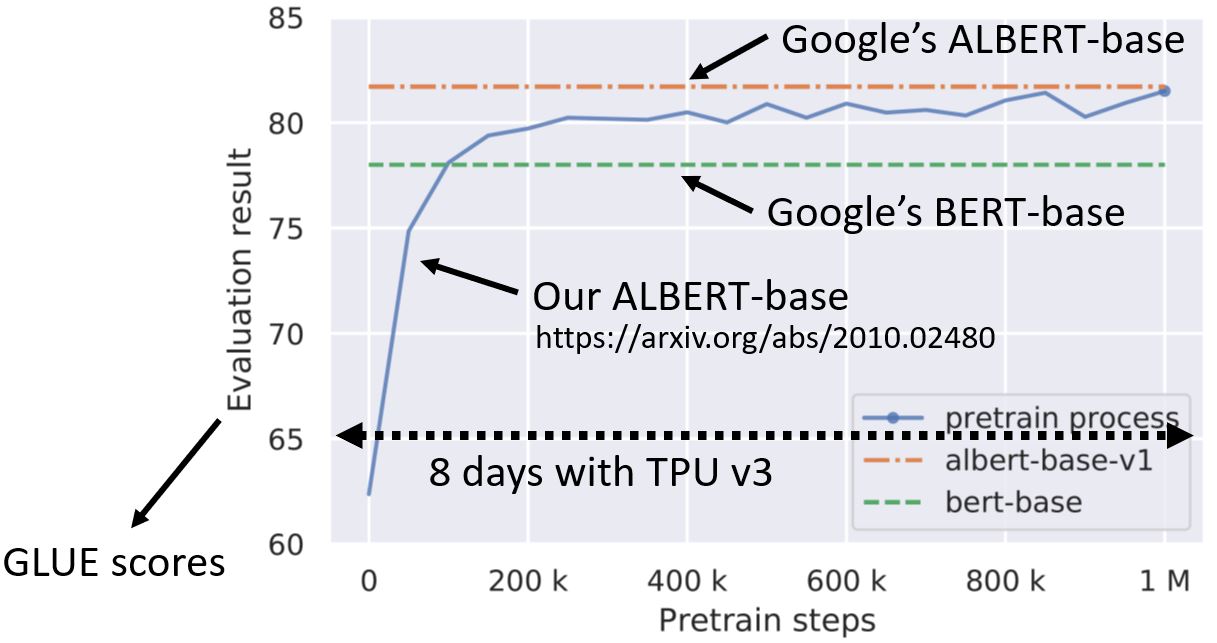
7.2.5 Why dose BERT work?